爬虫for循环中访问网址使用Xpath报错
最下方的薪资一栏也不知道为啥Xpath语法老是报错说我写的不对,可是我反复检查了好像也没啥问题
'''
网站https://www.shixiseng.com/interns?page=1&type=intern&keyword=%E9%A1%B9%E7%9B%AE%E7%BB%8F%E7%90%86&area&months&days°ree&official&enterprise&salary=-0&publishTime&sortType&city=%E5%85%A8%E5%9B%BD&internExtend
薪资、所在地、单位名称、所属行业、公司规模、福利标签、备注信息、企业性质的内容
'''
import requests
from lxml import etree
import pprint
import re
import urllib.request
import csv
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'}
url = 'https://www.shixiseng.com/interns?page=1&type=intern&keyword=%E9%A1%B9%E7%9B%AE%E7%BB%8F%E7%90%86&area&months&days°ree&official&enterprise&salary=-0&publishTime&sortType&city=%E5%85%A8%E5%9B%BD&internExtend'
data = requests.get(url, headers=headers).text
# 拿到网页源码
# print(data)
ele = etree.HTML(data)
div = ele.xpath('//div[@searchtype="intern"]')
# div = ele.xpath('/html/body/div[1]/div/div/div[2]/div[2]/div[1]/div[1]/div[1]/div[1]/div[1]')
# print(div,len(div))
# 获得薪资、所在地、单位名称、所属行业、公司规模、福利标签、备注信息、企业性质
# lst = []
for move in div:
# 所在地
location = move.xpath('./div[1]/div[1]/p[2]/span[1]/text()')
print(location)
# 单位名称
company = move.xpath('./div[1]/div[2]/p[1]/a[1]/@title')
print(company)
# 所属行业
industry = move.xpath('./div[1]/div[2]/p[2]/span[1]/text()')
print(industry)
# 福利标签
welfare = move.xpath('./div[2]/div[1]/span/text()')
print(welfare)
# 备注信息
notes = move.xpath('./div[2]/div[2]/span/text()')
print(notes)
# 薪资
href_list = move.xpath('./div[1]/div[1]/p[1]/a[1]/@href')
# print(href)
for href in href_list:
data_href = requests.get(href, headers=headers).text
# print(data_href)
ele_href = etree.HTML(data_href)
# print(ele_href)
salary = ele_href.xpath('//div[@class="job_msg"]/span[1]/text()"]')
print(salary)
# # 企业性质
# nature = ele_href.xpath('/html/body/div[1]/div/div/div[2]/div[1]/div[2]/div[2]/div[2]/div[2]/div[3]/div[2]/text()')
# print(nature)
# # 公司规模
# scale = ele_href.xpath('/html/body/div[1]/div/div/div[2]/div[1]/div[2]/div[2]/div[2]/div[2]/div[3]/div[3]/text()')
# print(scale)
# break
浏览器的开发者工具,可以自动产生 xpath,你可以用它产生了,复制过来

- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/692921
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:爬虫中xpath的返回空列表,xpath的长短和匹配问题
- 除此之外, 这篇博客: 关于爬虫中xpath返回为空的问题中的 关于爬虫中xpath返回为空的问题 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
测试环境:py3+win10,不同环境可能会有些许差异。
也是做个笔记吧,在爬取信息过程中,使用谷歌的xpath插件,是可以正常看到xpath返回的,网页内容返回也没有乱码,但在代码中使用xpath返回为空,这里的主要问题是tbody标签的问题,网页返回本身是没有这个标签(还是得仔细看),是浏览器规范html元素中加上的,所以xpath路径中使用tbody标签就返回空了。
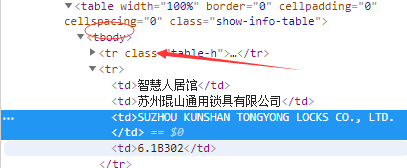
感谢博客园“沙漠的雨滴”关于这个问题的分享:
爬取网页
网页没啥反扒机制,直接上手就可以了。
http://shfair-cbd.no4e.com/portal/list/index/id/208.html?page=1代码如下:
import requests from lxml import etree import numpy as np import csv import time class BuildSpider(): def __init__(self,csv_name): self.csv_headers = ['类型','企业中文名','companyname','展位'] self.start_url = 'http://shfair-cbd.no4e.com/portal/list/index/id/208.html?page={}' self.headers = [{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"}, {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}, {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.7 Safari/537.36'} ] self.csv_name = csv_name def get_table_content(self,table_info): table_list = [] for each_sample in table_info: sample_info = each_sample.xpath("./td") temp_list = [] for each in sample_info: every_range = each.xpath("./text()") if len(every_range) == 0: every_range = '' else: every_range = every_range[0] temp_list.append(every_range) table_list.append(temp_list) return table_list def run(self): page = 1 with open(self.csv_name,'w',encoding='utf_8_sig',newline='') as f: writer = csv.writer(f) writer.writerow(self.csv_headers) while True: url = self.start_url.format(page) response = requests.get(url,headers=self.headers[np.random.randint(len(self.headers))]) content = response.content.decode() tree = etree.HTML(content) table_info = tree.xpath("//tr[position()<last() and position()>1]") table_values = self.get_table_content(table_info) writer.writerows(table_values) print('正在写入第{}页,当前访问url为:{}'.format(page,url)) print('当前写入内容为:{}'.format(table_values)) time.sleep(1+np.random.random()) if len(tree.xpath("//div/li[last()]/a/@href")) == 0: print('所有内容已经抓取完毕~~') break page += 1 if __name__ == '__main__': m = BuildSpider('d:/Desktop/test.csv') m.run()注意事项:
- xpath是从网页返回内容里边去提取的,网页返回的content和浏览器的element可能会有差异,当xpath无法正常提取内容时,我们首先可以将网页请求返回内容保存到本地在顺着xpath路径查看原因。
- 您还可以看一下 CSDN就业班老师的爬虫试听课课程中的 XPath语法与案例小节, 巩固相关知识点
- 以下回答来自chatgpt:
针对该问题,可能出现问题的原因有以下几种:
- 网站反爬虫,采取了注释标签等绕过爬虫的手段。
- Xpath语法有问题,在循环中访问网址时无法正确提取数据。
针对问题一,可以尝试在爬虫中加入伪装请求头,模拟人类访问,例如:
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3' }另外可以尝试使用代理IP等方法。
针对问题二,可以先通过chrome浏览器的开发者工具(F12)尝试在网页中手动提取数据,调试出正确的Xpath语法,再把语法复制到代码中。同时需要注意Xpath语法的基础知识,例如“/”、“//”等符号的含义,以及如何提取文本内容等。代码示例如下:
import requests from lxml import etree url = 'https://example.com' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3' } response = requests.get(url, headers=headers) html = etree.HTML(response.text) # 提取特定标签中的文本内容 names = html.xpath('//div[@class="name"]/text()') # 提取特定标签中的属性值 images = html.xpath('//img[@class="avatar"]/@src')
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^