深度学习研究生显卡推荐
是一张4070好呢还是两张3060对于深度学习跑模型提升大呢,希望大能回答
1.显存
4070具有12GB显存,而每3060的显存为12GB,两张共计24GB。然而,请注意,当使用多个显卡并行处理时,并不是所有深度学习框架都能完美地利用两张显卡的内存。因此,在某些情况下,4070的12GB显存可能对您的应用足够。
2.计算能力
4070的计算能力理论上应高于RTX 3060。尽管两张3060在某些情况下可能提供更高的总计算能力,但请注意多GPU设置可能需要更复杂的编程,并且并非所有深度学习框架都能完全利用这种设置。
3.功耗
4070的最大功耗为300W。每张3060的最大功耗约为170W,两张显卡共计340W。因此,两张3060的功耗和散热需求可能更高。
如果您的深度学习框架和应用程序能够充分利用多GPU设置,那么两张3060对于深度学习跑模型提升大。
- 这篇博客: 【毕业设计】基于机器学习与大数据的糖尿病预测中的 5.3 模型参数调优 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
Logistic模型调优:
C:C为正则化系数λ的倒数,必须为正数,默认为1。和SVM中的C一样,值越小,代表正则化越强。SVM模型调优:
C:惩罚系数,即对误差的宽容度。c越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差
gamma: 选择RBF函数作为kernel后,该函数自带的一个参数。隐含地决定了数据映射到新的特征空间后的分布,gamma越大,支持向量越少,gamma值越小,支持向量越多。支持向量的个数影响训练与预测的速度。XGBoost参数调优:
XGBoost的参数较多,这里对三个参数进行了调整,共分为两步调整。整体思路是先调整较为重要的一组参数,然后将调到最优的参数输入模型后继续调下一组参数。parameters_Logr = {'C':[0.05,0.1,0.5,1]} parameters_svm = {'C':[0.05,0.1,1,5,10,20,50,100],'gamma':[0.01,0.05,0.1,0.2,0.3]} # 网格搜索 grid_search_log = GridSearchCV(model_logistics,parameters_Logr, cv=5,scoring='roc_auc') grid_search_log.fit(train_X, train_y) grid_search_svm = GridSearchCV(model_svm,parameters_svm, cv=5,scoring='roc_auc') grid_search_svm.fit(X_train_minmax, train_y) # 获得参数的最优值 print('Log:\n') print(grid_search_log.best_params_,grid_search_log.best_score_) print('\nSVM:\n') print(grid_search_svm.best_params_,grid_search_svm.best_score_)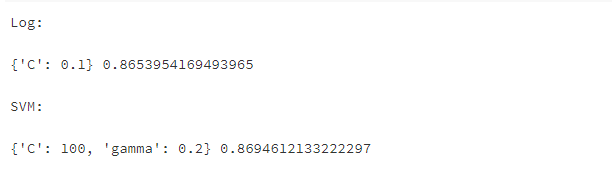
#XGBoost调参 #第一步:先调max_depth、min_child_weight param_test1 = { 'max_depth':range(3,10,2), 'min_child_weight':range(1,6,2) } gsearch1 = GridSearchCV(estimator = XGBClassifier(), param_grid = param_test1,scoring='roc_auc') gsearch1.fit(train_X,train_y,early_stopping_rounds=500, eval_metric="logloss", eval_set=eval_set, verbose=False) gsearch1.best_params_,gsearch1.best_score_
#第二步:调gamma param_test2 = { 'gamma':[0.01,0.05,0.1,0.2,0.3,0.5,1] } gsearch2 = GridSearchCV(estimator = XGBClassifier(max_depth=3,min_child_weight=3), param_grid = param_test2, scoring='roc_auc', cv=5) gsearch2.fit(train_X,train_y,early_stopping_rounds=500, eval_metric="logloss", eval_set=eval_set, verbose=False) gsearch2.best_params_, gsearch2.best_score_