yolov8训练时出现AttributeError: 'YOLO' object has no attribute 'load'
yolov8训练时出现AttributeError: 'YOLO' object has no attribute 'load'
如何解决?
这个错误可能是因为你的YOLO对象没有load属性,通常是因为你的代码中没有正确地实例化YOLO对象或者是没有正确地调用相关函数。
有几种可能的解决方法:
1.检查YOLO类的代码,确保它具有load方法,并且在实例化对象后可以正确地调用该方法。
2.检查你的代码,确保你已经正确地实例化了YOLO对象,如:
model = YOLO(...)
然后再使用load方法:
model.load(...)
3.检查你的代码,确保你没有错误地将YOLO对象的某个属性名称写错。例如,如果你的YOLO对象具有名为load_model的属性而不是load,那么你需要使用:
model.load_model(...)
而不是:
model.load(...)
希望这些解决方案能够帮助你解决问题。
- 这篇博客: yolo系列论文阅读中的 YOLOv1 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
yolov1提出了一种新的识别方法,不同于RCNN系列将识别问题转化为对候选区域的分类,yolo使用回归方法直接预测目标的类别和位置。


对输入的每幅图片,yolov1将之分割为7×7的网格,每个网格预测2个bounding boxes.对每个bounding box预测一个置信度(confidence scores),confidence scores定义为:

当包围盒中存在物体时Pr(Object)=1, 置信度为ground truth与bounding box的交并比,否则Pr(Object)=0.每个bounding box包含5个预测(x, y, w, h, confidence)。(x,y)表示bounding box的中心坐标,w, h表示bounding box的宽和高。
对每个网格进行类别预测:Pr(Classi|Object) , 表示该网格中包含各类物体的概率。注意:yolov1只对每个网格进行类别预测,而不是对每个bounding box进行类别预测。默认每个网格中只包含一个物体。若存在多个物体,则取交并比最大的一个计算。
每个网格目标识别的结果(哪个种类,概率是多少):
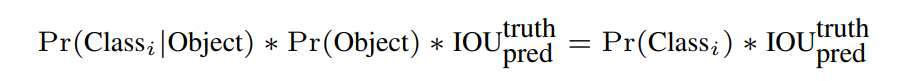
yolov1的网络结构:
网络使用一系列简单的3×3,1×1卷积,最后全连接层输出预测结果tensor。
由于目标识别通常需要细粒度的视觉信息,作者将网络的输入分辨率提高到了448×448(注意训练时依然用的224×224分辨率),网络输出为7×7×(20+5×2)的tensor。损失函数:

当bounding box中不包含物体时,Pr(Object)=0, 推动置信度为0,不包含物体梯度下降超过了包含物体的梯度,由于一幅图像中不包含物体的网格有很多,这样会在训练时造成梯度发散,模型不稳定。为了解决这个问题,增加坐标预测的权重,减少confidence sorces的预测权重。令λcoord=5, λnoobj=0.5。yolo优点:识别速度快,能够达到45帧/s,轻量级版本能够达到155帧/s, 准确度比上不足,比下有余。
yolo缺点:难以识别近距离的两个物体,和在同一网格内体积比较小的同类物体,如鸟群等。