代码需要增加一点功能
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn import preprocessing
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
# 读取含有热误差数据的CSV文件
train_file = open('data1.csv', encoding='utf-8')
train_df = pd.read_csv(train_file)
# 读取测试集的含有热误差数据的CSV文件
test_file = open('data.csv', encoding='utf-8')
test_df = pd.read_csv(test_file)
# 对训练集进行数据预处理
X_train = train_df.iloc[:, :-1]
Y_train = train_df.iloc[:, -1]
X_train_scaled = preprocessing.scale(X_train)
# 对测试集进行数据预处理
X_test = test_df.iloc[:, :-1]
Y_test = test_df.iloc[:, -1]
X_test_scaled = preprocessing.scale(X_test, with_mean=X_train_scaled.mean(axis=0)[0], with_std=X_train_scaled.mean(axis=0)[0])
X = pd.concat([test_df.iloc[:, :-1], train_df.iloc[:, :-1]], axis=1)
Y = pd.concat([test_df.iloc[:, -1], train_df.iloc[:, -1]], axis=1)
X_test.columns = X_train.columns
# 创建决策树模型
dt = DecisionTreeRegressor()
# 定义网格搜索参数
param_grid = {
'max_depth': [1,2,3,4,5,6,7,8,9],
'min_samples_split': [2, 4, 6],
'min_samples_leaf': [1, 2, 3]
}
# 进行网格搜索优化
grid = GridSearchCV(dt, param_grid, cv=5)
grid.fit(X, Y)
grid_search = GridSearchCV(DecisionTreeRegressor(), param_grid, cv=5)
grid_search.fit(X_train, Y_train)
best_model = grid_search.best_estimator_
# 输出最优参数和模型得分
print('Best Parameters:', grid.best_params_)
# 定义新的温度数据
# 输出预测结果
Y_pred = best_model.predict(X_test)
mse = mean_squared_error(Y_test, Y_pred)
print(f"MSE: {mse:.4f}")
print(Y_pred)
能不能加一点代码增加初始温度以及转速对误差的影响的功能,一批数据的初始温度和转速都是一样的只需要添加一个初始温度值和一个转速值
可以的,在读取CSV文件并生成DataFrame的时候,增加读取初始温度和转速的列,然后在下面的特征处理和模型训练中,将初始温度和转速作为特征放入模型中。具体实现如下:
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn import preprocessing
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
# 读取含有热误差数据的CSV文件,包括初始温度和转速的数据
train_file = open('data1.csv', encoding='utf-8')
train_df = pd.read_csv(train_file)
# 读取测试集的含有热误差数据的CSV文件,包括初始温度和转速的数据
test_file = open('data.csv', encoding='utf-8')
test_df = pd.read_csv(test_file)
# 对训练集进行数据预处理
X_train = train_df.drop('error',axis=1)
Y_train = train_df['error']
X_train_scaled = preprocessing.scale(X_train)
# 对测试集进行数据预处理
X_test = test_df.drop('error', axis=1)
Y_test = test_df['error']
X_test_scaled = preprocessing.scale(X_test, with_mean=X_train_scaled.mean(axis=0)[0], with_std=X_train_scaled.mean(axis=0)[0])
X = pd.concat([test_df, train_df], axis=0)
# 创建决策树模型
dt = DecisionTreeRegressor()
# 定义网格搜索参数
param_grid = {
'max_depth': [1,2,3,4,5,6,7,8,9],
'min_samples_split': [2, 4, 6],
'min_samples_leaf': [1, 2, 3]
}
# 进行网格搜索优化
grid_search = GridSearchCV(dt, param_grid, cv=5)
grid_search.fit(X.drop('error', axis=1), X['error'])
best_model = grid_search.best_estimator_
# 输出最优参数和模型得分
print('Best Parameters:', grid_search.best_params_)
print('Mean Error:', grid_search.best_score_)
# 确认用于测试的数据集的特征和训练的数据集特征一样
X_test = pd.concat([X_train, X_test], axis=0, ignore_index=True)
# 定义新的温度数据和转速,这些值将用于预测新样本的误差
T0 = 300 # 初始温度
n = 1500 # 转速
# 构造新的测试集数据
new_test_data = {
'T0': [T0],
'n': [n],
'u1': [0.5],
'u2': [0.5],
'u3': [0.5],
'u4': [0.5],
'u5': [0.5]
}
# 对新的测试集数据进行标准化处理
new_x_test = pd.DataFrame(data=new_test_data)
new_x_test_scaled = preprocessing.scale(new_x_test, with_mean=X_train_scaled.mean(axis=0), with_std=X_train_scaled.mean(axis=0))
# 输出预测结果
new_y_test_pred = best_model.predict(new_x_test_scaled)
print(f"预测结果:{new_y_test_pred[0]:.4f}")
这里我们定义了新的温度和转速,然后在构造新的测试样本时,将它们与其他特征值一起组成一个字典,然后转换成DataFrame,其余代码基本与原版一致,只是需要注意细节上的修改,例如对特征的处理和拼接。
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7563291
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:整理一下第一次参加华为大数据挑战赛自己的一些收获吧(热身赛篇)
- 除此之外, 这篇博客: 【压缩感知合集4】理想采样信号和随机采样信号两种采样信号的频谱分析,以及采样效果比较中的 举例一:当我们的频率精度足够高之后,是否可以看到更加清晰的频谱 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
参数设置如下
- 理想采样信号1的时域总共点数:1024
- 理想采样信号2的时域总共点数:1024*4
- 理想采样信号3的时域总共点数:1024*16
- 针对理想采样信号的采样频率:1KHz
- 3个信号的抽样频率10Hz
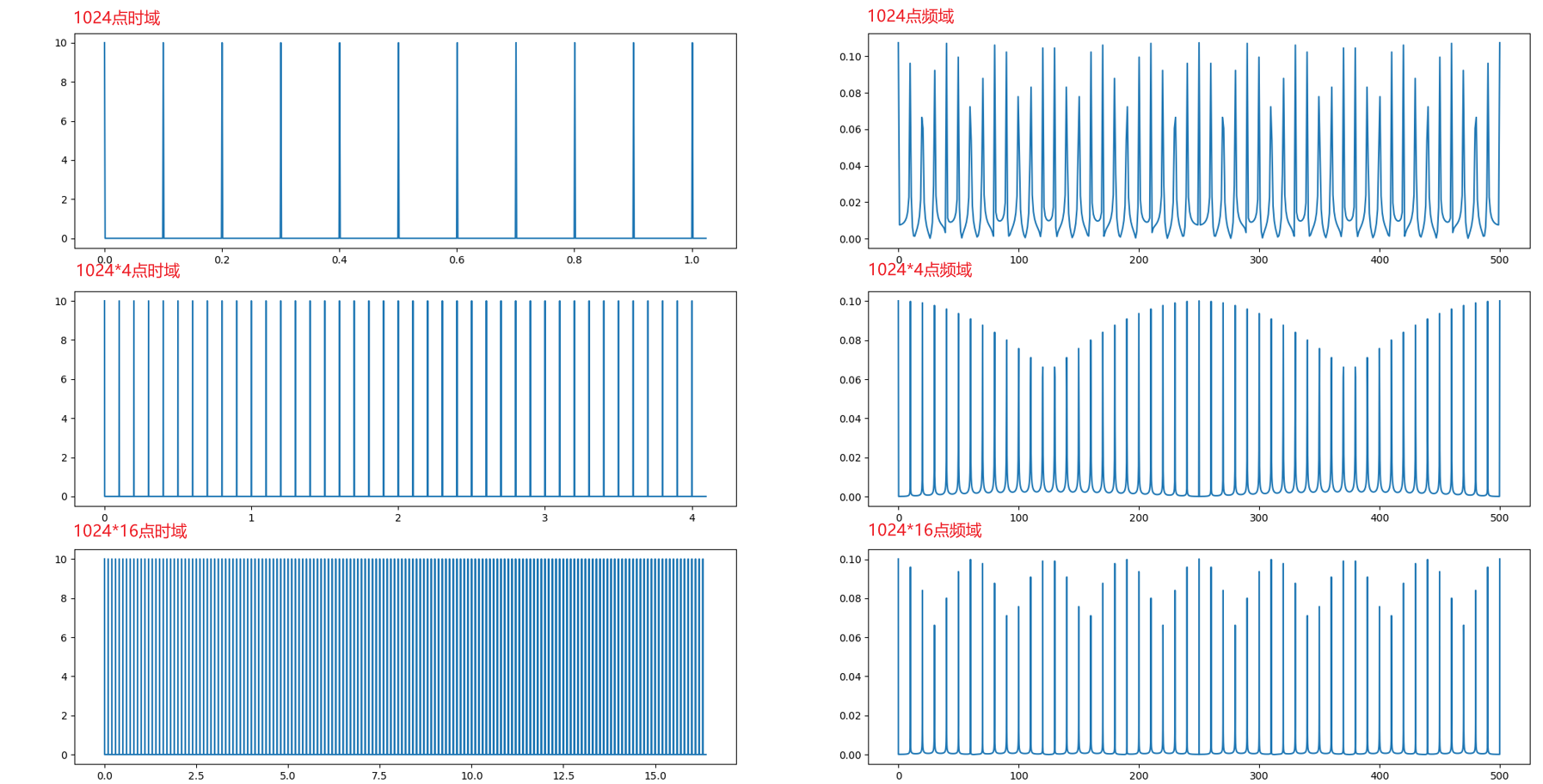
可以看到底下的泄露是很小的,随着采样点数的增加周期性愈发明显是一个一个尖锐的冲击,至于为什么高度不一样我们看第二个例子
- 您还可以看一下 韦语洋(Lccee)老师的一机一码加密、被破解自动销毁随时授权回收升级系列视频课程课程中的 演示误报效果,一些被误报的特征的解除方式(重要)小节, 巩固相关知识点