4和6应该填什么?求解答
from bs4 import BeautifulSoup
【1】 urllib import request
wwwd="【2】://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/?focus=book”#网页地址
res3=request.urlopen(【3】)#打开连接
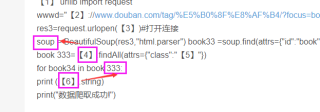
soup = BeautifulSoup(res3,"html.parser") book33 =soup.find(attrs={"id":"book"!)
book 333=【4】.findAll(attrs={"class":"【5】"})
for book34 in book 333:
print (【6】.string)
print("数据爬取成功!")
可以按照这个对照顺序去看,对应的变量名字是什么,填空就填什么
这个问题刚回答过?
from bs4 import BeautifulSoup
from urllib import request
address = "https://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/?focus=book" #网页地址
res3 = request.urlopen(address)
soup = BeautifulSoup(res3,"html.parser")
book3 = soup.find(attrs={ "id": "book" })
book31 = book3.findAll(attrs={ "class": "title" })
for book32 in book31:
print (book32.a.string)
print("数据爬取成功!")
from bs4 import BeautifulSoup
import urllib.request
url = "https://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/book"
res = urllib.request.urlopen(url)
soup = BeautifulSoup(res, "html.parser")
book_list = soup.find(attrs={"id": "book"})
book_items = book_list.findAll(attrs={"class": "title"})
for book in book_items:
print(book.string)
print("数据爬取成功!")
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/650202
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^