yolov5视频读取不了,说不存在

图片可以正常识别,视频就不可以了,想问一下是什么原因
非常感谢
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7689362
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:Yolov5自学笔记之一--从入门到入狱,功能强大不要乱用(实现yolov5的基本功能使用流程及训练自己的数据集)
- 除此之外, 这篇博客: YOLOv5 实现目标检测(训练自己的数据集实现猫猫识别)中的 一、概要 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
2020年6月10日,Ultralytics在github上正式发布了YOLOv5。YOLO系列可以说是单机目标检测框架中的潮流前线了,YOLOv5并不是一个单独的模型,而是一个模型家族,包括了YOLOv5s(最小)、YOLOv5m、YOLOv5l、YOLOv5x(最大)。目前v6.0版本又新增一层YOLOv5n模型,代替YOLOv5s成为最小模型,在所有模型中速度更快但精度也更低。
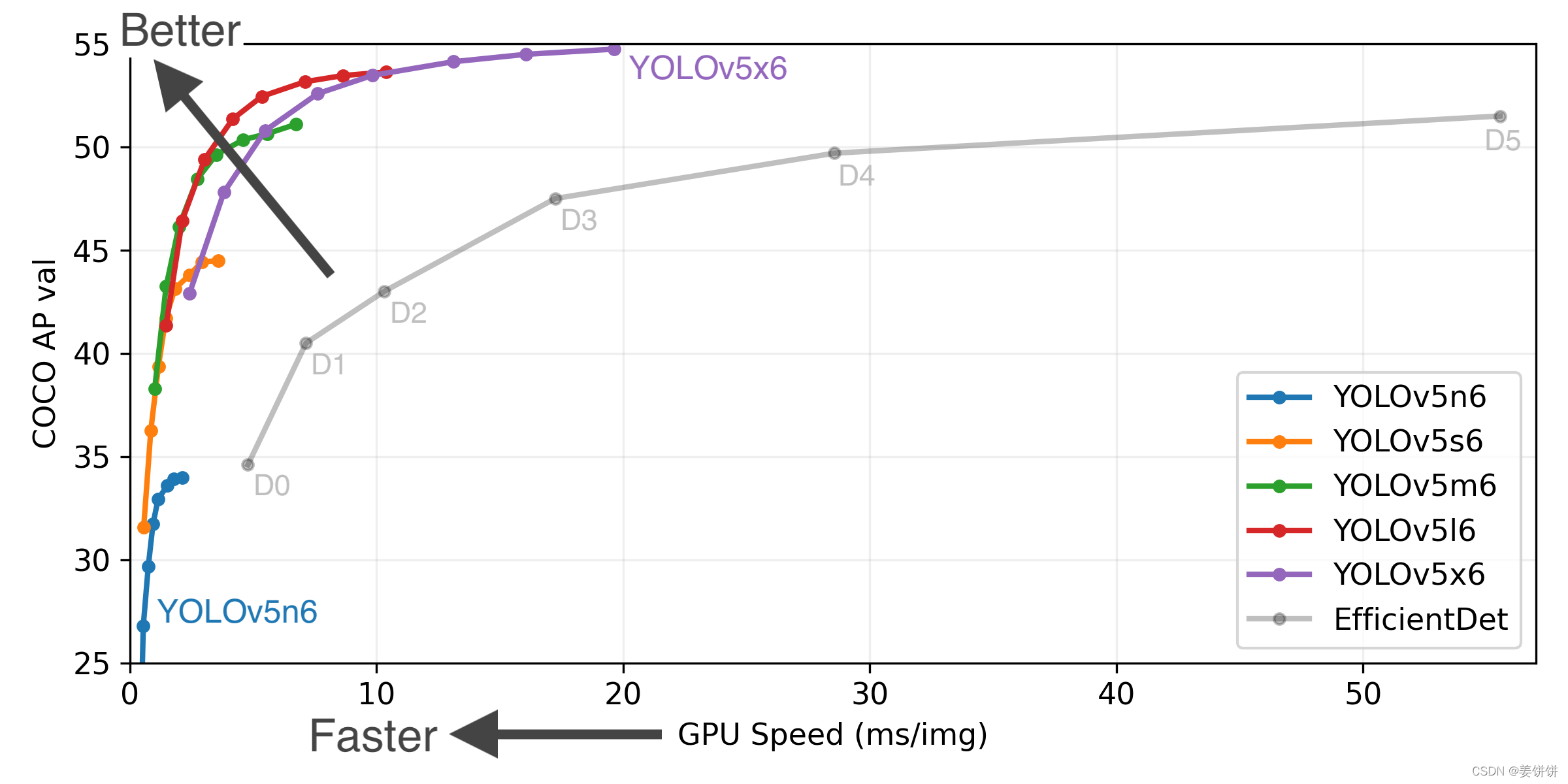
由于YOLOv5是在PyTorch中实现的,它受益于成熟的PyTorch生态系统,支持更简单,部署更容易,相对于YOLOv4,YOLOv5具有以下优点:- 速度更快。在YOLOv5 Colab notebook上,运行Tesla
P100,我们看到每张图像的推理时间仅需0.007秒,这意味着每秒140帧(FPS),速度是YOLOv4的2倍还多。 - 精度更高。在Roboflow对血细胞计数和检测(BCCD)数据集的测试中,只训练了100个epochs就达到了大约0.895的平均精度(mAP)。诚然EfficientDet和YOLOv4的性能相当,但在准确率没有任何损失的情况下,看到如此全面的性能提升是非常罕见的。
- 体积更小。YOLOv5的权重文件是27兆字节。YOLOv4(采用Darknet架构)的权重文件是244兆。YOLOv5比YOLOv4小了近90%!这意味着YOLOv5可以更容易地部署到嵌入式设备上。
既然YOLOv5如此之棒,那我们就体验以下大神们的开源成果吧!
github地址:https://github.com/ultralytics/yolov5 [不到1M]
大神们还很贴心的把官方模型放到了网上,如果有梯子,可以下载下来直接测试一下,YOLOv5所有版本的源码和官方模型的下载地址:https://github.com/ultralytics/yolov5/tags。博主这边没梯子,不过也无关紧要啦,毕竟我们用YOLOv5是识别具体的某项东西,需要自己用数据集来训练模型,官方给的模型也不一定适合我们的业务场景。
至于YOLOv5的原理这里就不多讲了(其实是讲不清),感兴趣的可以自行搜索。话不多说,直接上干货!

- 速度更快。在YOLOv5 Colab notebook上,运行Tesla
- 您还可以看一下 白勇老师的YOLOv5实战口罩佩戴检测课程中的 测试训练出的网络模型及性能统计小节, 巩固相关知识点
路径给错了,检查下source这个参数的路径
以下内容部分参考ChatGPT模型:
你好,关于yolov5无法读取视频的问题,可能是由于视频文件路径不正确或者视频编解码器不支持所导致的。你可以检查视频文件路径是否正确,或者尝试更换视频编解码器。以下是一个示例代码,可以读取视频文件并将其传递给yolov5进行目标检测:
import cv2
import torch
from yolov5 import detect
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# 打开视频文件
cap = cv2.VideoCapture('video.mp4')
while True:
# 读取视频帧
ret, frame = cap.read()
if not ret:
break
# 目标检测
results = detect(model, frame)
# 在图像上绘制检测结果
for result in results:
cv2.rectangle(frame, (result[0], result[1]), (result[2], result[3]), (0, 255, 0), 2)
# 显示图像
cv2.imshow('frame', frame)
if cv2.waitKey(1) == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
在这个示例代码中,我们首先加载了yolov5模型,然后打开了视频文件,并循环读取每一帧。对于每一帧,我们调用了yolov5进行目标检测,并在图像上绘制检测结果。最后,我们显示了带有检测结果的图像,直到用户按下q键退出程序。