泛型的实际应用,该怎么敲?
这用泛型该怎么做?不太懂泛型的实际应用,要是用了泛型,该怎么定义数组存储?成员变量又该怎么处理?望代码


这个你定义2个类,Person1类,拥有姓名性别年龄三个字段
Person2类,拥有姓名电话字段
然后排序算法 T 代表任意类型
找了一个类似的例子,你看下
public class Person1 {
private String name;
private String gender;
private int age;
public Person1(String name, String gender, int age) {
this.name = name;
this.gender = gender;
this.age = age;
}
public String getName() {
return name;
}
public String getGender() {
return gender;
}
public int getAge() {
return age;
}
}
public class Person2 {
private String name;
private String phone;
public Person2(String name, String phone) {
this.name = name;
this.phone = phone;
}
public String getName() {
return name;
}
public String getPhone() {
return phone;
}
}
public class Sorter {
public interface Selector<T> {
int compare(T obj1, T obj2);
}
public static <T> void sort(T[] data, Selector<T> selector) {
int len = data.length;
for (int i = 0; i < len - 1; i++) {
boolean flag = true;
for (int j = 0; j < len - 1 - i; j++) {
if (selector.compare(data[j], data[j + 1]) > 0) {
T temp = data[j];
data[j] = data[j + 1];
data[j + 1] = temp;
flag = false;
}
}
if (flag) {
break;
}
}
}
}
调用
Person1[] persons1 = {
new Person1("Amy", "Female", 25),
new Person1("Bob", "Male", 30),
new Person1("Charlie", "Male", 20),
new Person1("David", "Male", 35),
new Person1("Emily", "Female", 28)
};
Sorter.sort(persons1, new Sorter.Selector<Person1>() {
public int compare(Person1 obj1, Person1 obj2) {
if (obj1.getAge() > obj2.getAge()) {
return 1;
} else if (obj1.getAge() < obj2.getAge()) {
return -1;
} else {
return 0;
}
}
});
for (Person1 p : persons1) {
System.out.println(p.getName() + " " + p.getGender() + " " + p.getAge());
}
System.out.println();
Person2[] persons2 = {
new Person2("Amy", "123456"),
new Person2("Bob", "234567"),
new Person2("Charlie", "345678"),
new Person2("David", "456789"),
new Person2("Emily", "567890")
};
Sorter.sort(persons2, new Sorter.Selector<Person2>() {
public int compare(Person2 obj1, Person2 obj2) {
return obj1.getName().compareTo(obj2.getName());
}
});
for (Person2 p : persons2) {
System.out.println(p.getName() + " " + p.getPhone());
}
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/268296
- 这篇博客你也可以参考下:什么时候使用请求转发?而什么时候又该使用请求重定向?请求转发和请求重定向的区别,及使用
- 除此之外, 这篇博客: 微信一面:一致性哈希是什么,使用场景,解决了什么问题?中的 使用哈希算法有什么问题? 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
有的同学可能很快就想到了:哈希算法。因为对同一个关键字进行哈希计算,每次计算都是相同的值,这样就可以将某个 key 确定到一个节点了,可以满足分布式系统的负载均衡需求。
哈希算法最简单的做法就是进行取模运算,比如分布式系统中有 3 个节点,基于 hash(key) % 3 公式对数据进行了映射。
如果客户端要获取指定 key 的数据,通过下面的公式可以定位节点:
hash(key) % 3如果经过上面这个公式计算后得到的值是 0,就说明该 key 需要去第一个节点获取。
但是有一个很致命的问题,如果节点数量发生了变化,也就是在对系统做扩容或者缩容时,必须迁移改变了映射关系的数据,否则会出现查询不到数据的问题。
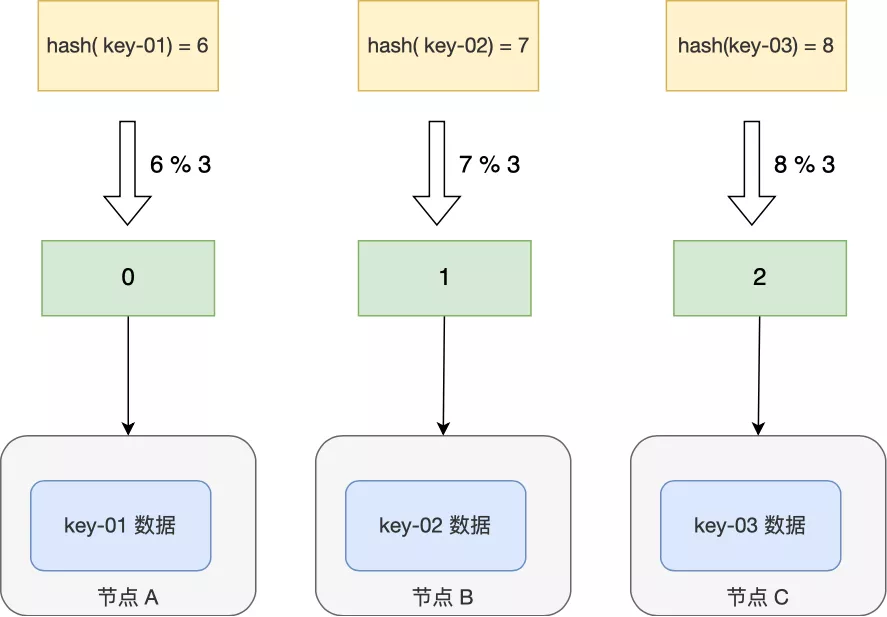
举个例子,假设我们有一个由 A、B、C 三个节点组成分布式 KV 缓存系统,基于计算公式 hash(key) % 3 将数据进行了映射,每个节点存储了不同的数据:

现在有 3 个查询 key 的请求,分别查询 key-01,key-02,key-03 的数据,这三个 key 分别经过 hash() 函数计算后的值为 hash( key-01) = 6、hash( key-02) = 7、hash(key-03) = 8,然后再对这些值进行取模运算。
通过这样的哈希算法,每个 key 都可以定位到对应的节点。
当 3 个节点不能满足业务需求了,这时我们增加了一个节点,节点的数量从 3 变化为 4,意味取模哈希函数中基数的变化,这样会导致大部分映射关系改变,如下图:
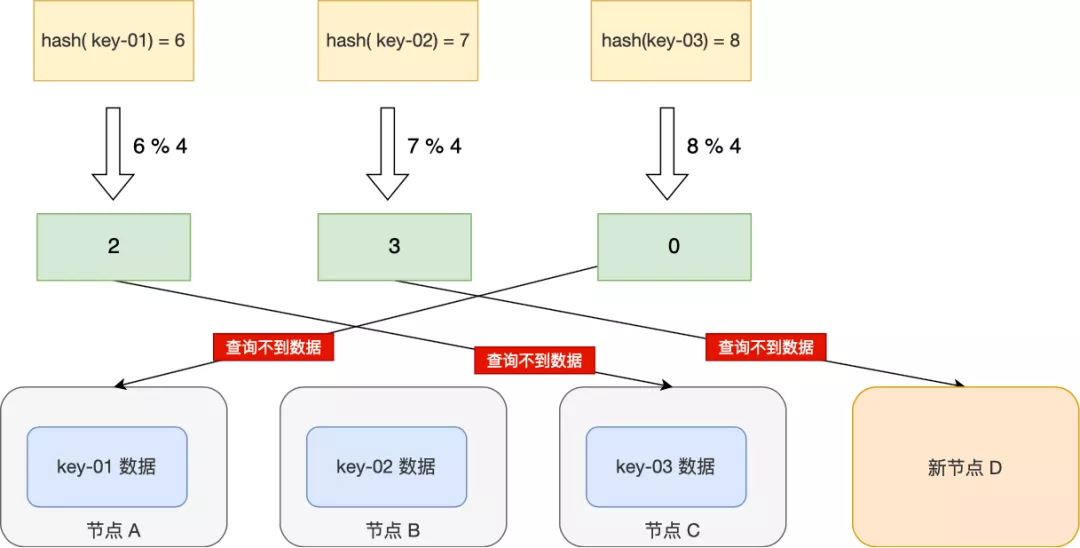
比如,之前的 hash(key-01) % 3 = 0,就变成了 hash(key-01) % 4 = 2,查询 key-01 数据时,寻址到了节点 C,而 key-01 的数据是存储在节点 A 上的,不是在节点 C,所以会查询不到数据。
同样的道理,如果我们对分布式系统进行缩容,比如移除一个节点,也会因为取模哈希函数中基数的变化,可能出现查询不到数据的问题。
要解决这个问题的办法,就需要我们进行迁移数据,比如节点的数量从 3 变化为 4 时,要基于新的计算公式 hash(key) % 4 ,重新对数据和节点做映射。
假设总数据条数为 M,哈希算法在面对节点数量变化时,最坏情况下所有数据都需要迁移,所以它的数据迁移规模是 O(M),这样数据的迁移成本太高了。
所以,我们应该要重新想一个新的算法,来避免分布式系统在扩容或者缩容时,发生过多的数据迁移。
- 您还可以看一下 张传波老师的软件设计是怎样炼成的?课程中的 什么是漂亮的软件设计?小节, 巩固相关知识点
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^