关于Group By 问题

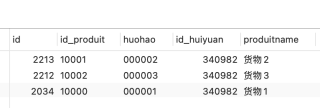
这个是我数据库表的结构及数据
我需要读出id_huiyuan=340982,的数据,如果有重复,则只显示一条。
这个是我目前的SQL,这样的写法,是只能读出“货物2”,“货物3”,货物1没有读出来
```sql
sql="select * from sell where ID In (Select Max(ID) from sell Group By huohao) and id_huiyuan=340982 order by id desc"
```
子查询里面的问题
select * from sell where ID In (Select Max(ID) from sell where
id_huiyuan=340982 Group By huohao) and id_huiyuan=340982 order by id desc
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/164996
- 你也可以参考下这篇文章:sql使用group by报错的解决方法
- 除此之外, 这篇博客: 一次对group by时间导致的慢查询的优化中的 2、SQL执行计划内容简述: 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
查看执行计划时,主要看上图中花圈的那三项数据即可:
type:访问类型,这是sql查询优化中一个很重要的指标,结果值从好到坏依次是:

Rows:数据行,根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数;
Extra:额外信息,SQL执行时十分重要的额外信息,简单说几个常会出现的值:
- Using filesort : 未利用到索引的默认排序,需要使用文件辅助进行排序,出现其说明SQL性能不好;
- Using temporary:使用临时表保存中间结果,常见于 group by ,出现其说明SQL性能不好;
- Using index: 说明可以直接在索引树上就能得到最终的值,避免了回表,出现其说明SQL性能很好;
- Using index for group-by:表示使用了 松散索引扫描 ,出现其说明SQL性能很好;因为松散索引扫描只需要读取很少量的数据就可以完成group by操作,所以执行效率非常高;
- select tables optimized away: 在没有group by子句的情况下,基于索引优化 MIN/MAX 聚合函数操作,不必等到执行阶段在进行计算,查询执行计划生成的阶段即可完成优化,出现其说明SQL性能达到最优,往往配合 type访问类型的system 出现;