报错功能名称与拟合期间传递的名称不匹配
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn import preprocessing
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
# 读取含有热误差数据的CSV文件
file1 = open('data1.csv',encoding='utf-8')
df1 = pd.read_csv(file1)
file2 = open('data.csv',encoding='utf-8')
df2 = pd.read_csv(file2)
# 对数据进行预处理
x = df1.iloc[:, :-1] # 输入变量
y = df1.iloc[:, -1] # 输出的热误差值
z = df2.iloc[:, :-1] # 输入变量
t = df2.iloc[:, -1] # 输出的热误差值
X=x+z
Y=y+t
X_scaled = preprocessing.scale(X) # 对输入变量进行标准化,避免某些维度权值过大或过小
# 划分数据集
X_train, X_test, Y_train, Y_test =x,z,y,t
# 创建决策树模型
model = DecisionTreeRegressor(max_depth=7)
#训练模型a
model.fit(X_train, Y_train)
param_grid = {
'max_depth': [6,7,8],
'min_samples_split': [2, 4, 6],
'min_samples_leaf': [1, 2, 4],
}
grid_search = GridSearchCV(DecisionTreeRegressor(), param_grid, cv=5)
grid_search.fit(X_train, Y_train)
best_model = grid_search.best_estimator_
# 预测结果
Y_pred = model.predict(X_test)
print(Y_pred)
# 评估模型
mse = mean_squared_error(Y_test, Y_pred)
print('MSE:', mse)
有没有兄弟帮忙看看下面的错误是什么原因该怎么改
ValueError: The feature names should match those that were passed during fit.
Feature names unseen at fit time:
- 5.31
- 5.5
- 5.69
- 5.81
- 5.81.1
- ...
Feature names seen at fit time, yet now missing:
- 5.75
- 6.13
- 6.19
- 6.25
- 6.38
- ...
以下回答引用自chatGpt, 有用的话,请采纳哇,这对我很重要!!!
根据错误提示,可以看到训练模型时传递的输入特征名称与测试时的特征名称不匹配。具体来说,训练模型时使用了X_train作为输入特征,而测试时使用了X_test作为输入特征,这两个特征的列名并不相同。因此,需要将X_test的列名修改为与X_train相同的列名。
具体的解决方法可以按照以下步骤进行:
1, 将X_train和X_test的列名打印出来,查看它们的列名是否一致。
print(X_train.columns)
print(X_test.columns)
2, 如果列名不一致,可以将X_test的列名修改为与X_train相同的列名。
X_test.columns = X_train.columns
3,重新运行模型,查看是否仍然有错误。
该回答通过自己思路及引用到GPTᴼᴾᴱᴺᴬᴵ搜索,得到内容具体如下:
这个错误是因为在GridSearchCV中使用了新的特征,但是在训练模型时没有使用这些特征。
具体来说,你在使用GridSearchCV时,使用了X_train和Y_train来训练模型,然后在测试集上进行预测。但是,在GridSearchCV中,你传递了包含新特征的参数,在训练过程中,这些新特征没有被使用,因此导致了该错误。
要解决这个问题,你需要确保在训练模型时使用与GridSearchCV中传递的所有特征名称匹配的特征。你可以在训练模型之前将X_train和Y_train与包含在GridSearchCV参数中的所有特征合并,以确保训练模型时使用了所有特征。
下面是修改后的代码:
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn import preprocessing
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
# 读取含有热误差数据的CSV文件
df1 = pd.read_csv('data1.csv')
df2 = pd.read_csv('data.csv')
# 合并所有特征
X = pd.concat([df1.iloc[:, :-1], df2.iloc[:, :-1]], axis=1)
Y = df1.iloc[:, -1] + df2.iloc[:, -1]
# 对输入变量进行标准化,避免某些维度权值过大或过小
X_scaled = preprocessing.scale(X)
# 划分数据集
X_train, X_test, Y_train, Y_test = train_test_split(X_scaled, Y, test_size=0.2, random_state=42)
# 创建决策树模型
model = DecisionTreeRegressor(max_depth=7)
# 训练模型
model.fit(X_train, Y_train)
# 设置GridSearchCV参数
param_grid = {
'max_depth': [6, 7, 8],
'min_samples_split': [2, 4, 6],
'min_samples_leaf': [1, 2, 4],
}
# 创建GridSearchCV对象
grid_search = GridSearchCV(model, param_grid, cv=5)
# 训练GridSearchCV模型
grid_search.fit(X_train, Y_train)
# 获取最佳模型
best_model = grid_search.best_estimator_
# 预测结果
Y_pred = best_model.predict(X_test)
# 评估模型
mse = mean_squared_error(Y_test, Y_pred)
print('MSE:', mse)
在这个修改后的代码中,我们首先合并了所有特征,然后对其进行了标准化。接下来,我们使用train_test_split函数将数据集划分为训练集和测试集,并创建了决策树模型。然后,我们将模型传递给GridSearchCV对象,设置参数,并使用训练集训练GridSearchCV模型。最后,我们使用最佳模型在测试集上进行预测并评估模型的性能。
如果以上回答对您有所帮助,点击一下采纳该答案~谢谢
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7451332
- 这篇博客你也可以参考下:对数据集随机抽取图片并且更改数据集文件中的图片名
- 除此之外, 这篇博客: 小白理解条件随机场用于命名实体识别的任务中中的 2. 什么是条件随机场呢? 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
我们举个例子来看下,CRF进行命名实体识别时,所做的序列标注任务是如何完成的!!
首先CRF是在HEM和HMM的基础上,构建了一个条件概率模型来分割和标记序列数据,可以根据给定的观察序列来预测对应的状态序列,且目标函数同时考虑输入的状态特征函数和标签转移特征函数,所以被广泛应用于NER的问题中。CRF应用到命名实体识别的任务中主要是根据BLSTM模型的预测输出序列求出使得目标函数最优化的序列。
X与Y是随机变量,在给定X的条件下,如果每个随机变量Y_v满足未来状态的条件概率与过去状态是条件独立,仅依赖于当前状态,如公式(1)
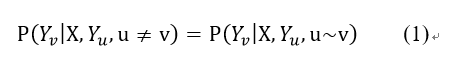
则(X,Y)为一个CRF。常用的一阶链式结构CRF如下图1所示: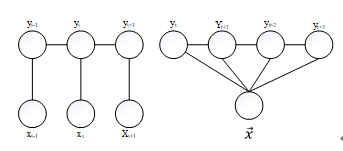
图1 条件随机场一阶链式结构
在自然语言处理的领域中,CRF是用于预测与输入序列相对应标注序列的概率化模型,在命名实体识别上有很好的应用。给定文本序列x={x_1,x_2,⋯,x_n}和根据BERT-BLSTM模型的输出预测序列y={y_1,y_2,⋯,y_n},通过条件概率P(y/x)进行建模,则有式(2)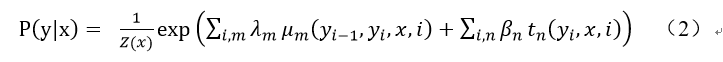
其中,i表示当前节点在序列中的索引,m,n表示在当前节点i上的特征函数总个数。 t_n表示节点特征函数,只和当前位置有关。μ_m表示局部特征函数,只与当前节点和上一个节点位置有关。β_n λ_m分别表示特征函数t_n和μ_m对应的权重系数,用于衡量特征函数的信任度。Z(x)为归一化因子,如式(3):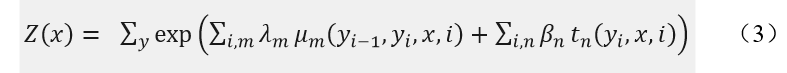
CRF能够通过考虑相邻之间标签的关系得到全局最优的标记序列,为对比分析模型有效性,本文采用最优化方法最大似然估计损失函数,在对条件概率建模的基础上,使用维特比算法解码得到全局最优的标注序列,得到命名实体。基于CRF的命名实体识别模型如下图2所示:
图2 基于CRF命名实体识别模型- 您还可以看一下 吴刚老师的【吴刚大讲堂】电商应用界面设计课程中的 列表页视觉设计的文案梳理方法小节, 巩固相关知识点