打印出来和谷歌显示的不一样
如下是我写的:
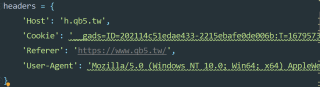
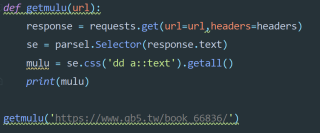
这个是的截图:

明明是里面这个标签为什么取不出来,我打印出来和谷歌查看的也不一样,为什么谷歌查看有dd标签,打印出来没有呢
https://img-mid.csdnimg.cn/release/static/image/mid/ask/111879349086197.png "#left")
这个是网址:https://www.qb5.tw/book_66836/
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7529817
- 这篇博客你也可以参考下:数据可视化头歌平台
- 除此之外, 这篇博客: 爬虫入门经典(十) | 一文带你快速爬取网易云音乐中的 2.2 爬歌手数据 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
- 1. 分析
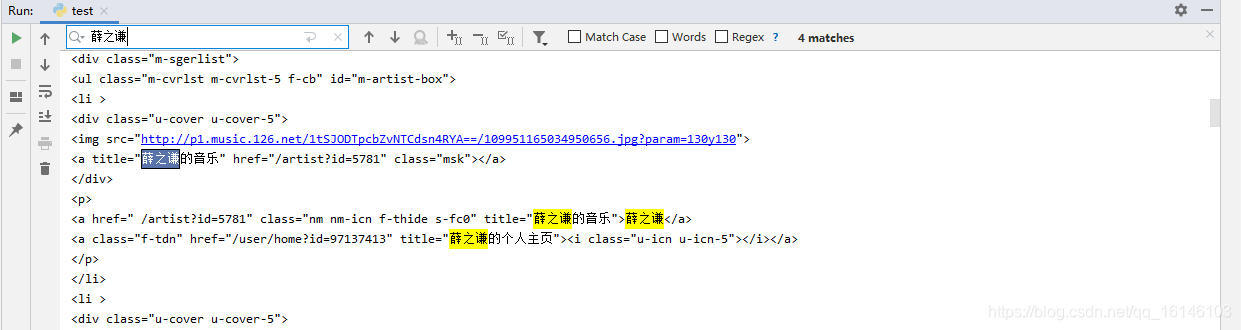
把此部分的源码拿出来
<a href=" /artist?id=5781" class="nm nm-icn f-thide s-fc0" title="薛之谦的音乐">薛之谦</a> <a class="f-tdn" href="/user/home?id=97137413" title="薛之谦的个人主页"><i class="u-icn u-icn-5"></i></a>- 2. 代码
def get_data(url, type_name): """爬歌手数据""" item = { "type": type_name, "name": "", "url": "" } html = parse_url(url) etree_obj = parse_html(html) artist_name_list = etree_obj.xpath('//a[@class="nm nm-icn f-thide s-fc0"]/text()') artist_url_list = etree_obj.xpath('//a[@class="nm nm-icn f-thide s-fc0"]/@href') data_zip = zip(artist_name_list, artist_url_list) for data in data_zip: item["name"] = data[0] item["url"] = base_url + data[1][1:] items.append(item)
我们通过观察,发现歌手正好是100个,说明我们已经成功拿到数据了。
- 1. 分析
前两个都没有
第三个哪个音乐的我这个谷歌可以显示,但是取不出来什么情况啊