关于#python#的问题:python爬虫
请问为什么这个代码只能爬取每一页的第一条评论啊?是循环有什么问题吗?求解。
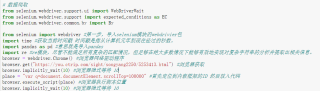
def drag_code(self):
time.sleep(0.5) #在执行查询之前,加一个延时time.sleep(0.5) #在执行查询之前,加一个延时
image_info = self.track.get_image()
all_comments = [] #所有评论
xingji = []
shijian = []
zp_time = []
tp_ner = []
zhichi = []
huifu = []
for i in range(13):
for j in range(1,11):
all_comments.append(browser.find_element(By.XPATH, "//div[@class = 'commentList']/div[@class = 'commentItem']/div[@class = 'contentInfo']/div[@class='commentDetail']".format(j)).text)
xingji.append(browser.find_element(By.XPATH, "//div[@class = 'commentList']/div[@class = 'commentItem']/div[@class = 'contentInfo']/div[@class = 'scroreInfo']/span[@class = 'averageScore']".format(j)).text)
shijian.append(browser.find_element(By.XPATH, "//div[@class = 'commentList']/div[@class = 'commentItem']/div[@class = 'contentInfo']/div[@class = 'commentFooter']/div[@class='commentTime']".format(j)).text)
bot = browser.find_element(By.XPATH, "//div[@class = 'poiDetailPage']/div[@class = 'moduleWrap']/div[@class = 'mainModule']/div[@class = 'commentModuleRef']/div[@class = 'commentModule normalModule']/div[@class = 'myPagination']/ul[@class = 'ant-pagination']/li[@class = ' ant-pagination-next']/span[@class = 'ant-pagination-item-comment']")
browser.execute_script("arguments[0].click();",bot)#通过XPath定位败#浏览器执行脚本
time.sleep(2)#使当前正在执行的Python程序进入睡眠或延迟几秒钟。
browser.implicitly_wait(3)#浏览器隐式等待 3
print(i)

根据代码片段,您的问题可能出现在XPath表达式上。您在获取评论列表的Xpath表达式中使用了.format(j),但是您并没有在字符串中使用花括号来表示要替换的值。因此,.format(j)部分被忽略了,只使用了原始的XPath表达式。
正确的XPath表达式应该包含一个花括号,用于表示要替换的值。例如,您可以这样修改XPath表达式:
"//div[@class='commentList']/div[@class='commentItem'][{0}]/div[@class='contentInfo']/div[@class='commentDetail']"
然后,在获取评论文本时,使用以下代码:
for j in range(1,11):
xpath = "//div[@class='commentList']/div[@class='commentItem'][{0}]/div[@class='contentInfo']/div[@class='commentDetail']".format(j)
all_comments.append(browser.find_element(By.XPATH, xpath).text)
同样地,您还需要相应地修改其他XPath表达式,以确保它们包含花括号并使用正确的值进行替换。
希望这可以帮助您解决问题。
不知道你这个问题是否已经解决, 如果还没有解决的话:- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7582155
- 你也可以参考下这篇文章:Python基础:什么是字符串?字符串是用来做什么的?
- 同时,你还可以查看手册:python- 走向编程的第一步 中的内容
- 除此之外, 这篇博客: Python图像处理是没有任何一门编程语言能比得上的!为什么这么说呢?看完这篇你就知道了!中的 裁剪图像 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
我们将从裁剪图像开始。当要裁剪图像时,需要一个区域来定义要裁剪的区域。我们来编码吧!
image = Image.open("tux.jpg") box = (250, 200, 550, 600) cropped = image.crop(box) cropped.show()我们已经开张了Tux.jpg作为第一种情况,当我们裁剪图像时,框是要使用的区域。作为最后一次,我们将该框作为参数传递给作物()方法。您可能会得到这样的输出:


转存失败
重新上传取消
- 您还可以看一下 刘顺祥老师的Python数据分析与挖掘课程中的 爬虫的套路有哪些?小节, 巩固相关知识点

如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^