Python问题,求解答
当我将一个csv文件改写成另一个文件名,并想要读其中几行数据时总是不能成功运行,请问这是怎么回事呢

该回答通过自己思路及引用到GPTᴼᴾᴱᴺᴬᴵ搜索,得到内容具体如下:
可能存在多种原因导致您无法成功读取CSV文件中的数据,下面列出一些常见的原因和解决方法供您参考:
1. 文件名或路径错误
请确保您输入的文件名或路径是正确的,包括文件名的大小写、文件类型和路径分隔符等。
2. 文件未关闭
在读取CSV文件时,如果您没有关闭文件,可能会导致文件被占用而无法读取。因此,在读取完文件后,请记得执行`file.close()`关闭文件。
3. 编码问题
如果CSV文件的编码格式与您的Python代码不一致,可能会导致无法正确读取文件。在使用`open()`函数打开CSV文件时,可以指定编码格式,例如:`open('file.csv', encoding='utf-8')`。
4. 行末尾缺少换行符
如果CSV文件的最后一行没有换行符,可能会导致无法读取最后一行数据。在读取CSV文件时,可以使用`csv.reader()`函数,该函数会自动处理行末尾缺少换行符的问题。
5. 文件不存在
请确保您要读取的CSV文件存在,如果文件不存在,Python会抛出`FileNotFoundError`异常。
6. 权限问题
如果您没有读取CSV文件的权限,可能会导致无法读取文件。请确保您有读取文件的权限,或者尝试将CSV文件复制到另一个目录中再尝试读取。
如果您仍然无法读取CSV文件中的数据,可以通过捕获异常来查看具体的错误信息,例如:
import csv
try:
with open('file.csv', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
print(row)
except Exception as e:
print('Error:', e)
这样可以输出具体的错误信息,有助于您找到问题所在并解决。
如果以上回答对您有所帮助,点击一下采纳该答案~谢谢
贴出你的报错信息看下,另外csv文件本身是否有问题
报什么错吗?你把文件放到一个不含中文的文件路径下试试呢。
1.文件名或路径错误
2.文件是否被占用
我能想到的只有这两种原因
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7657253
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:解决用python将数据写入csv文件隔一行空行问题
- 同时,你还可以查看手册:python-csv --- CSV 文件读写 中的内容
- 除此之外, 这篇博客: Python构建共现矩阵并将其三元组形式存储至csv文件中的 引言:共现矩阵有什么用? 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
主要用于发现主题,解决词向量相近关系的表示;
将共现矩阵行(列)作为词向量,其表现形式类似于数据结构中图论里学的邻接矩阵。在本文中,笔者主要用来统计会议论文作者之间的合作关系。
【举例】:假设有四篇论文,每篇论文作者名字如下。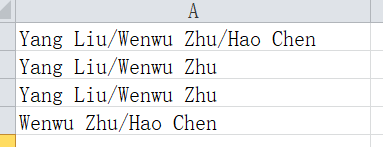
我们根据上述原始数据构建如下共现矩阵,由如下矩阵可以看出,Yang Liu和Wenwu Zhu在上述窗口中共同出现(co-occurrence)过3次,其实际含义为这两个作者进行过3次合作,共现的次数越多,我们就认为这两个人的合作关系越紧密,对应权值也就越高。同理,Yang Liu和Hao Chen共现过1次、Wenwu Zhu和Hao Chen共现过2次。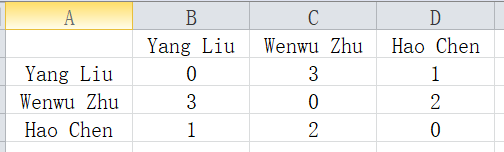
当数据规模很庞大的时候(如2000+个作者),再用矩阵的形式来表示其关系就不太合适,而对于稀疏矩阵的存储方法,可以借用数据结构中三元组的形式来存储,具体方式如下图: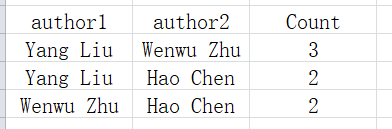
而Python(其他语言也可)自带的数据结构——字典,就可以很方便的将原始数据转换成三元组形式。 - 您还可以看一下 李云老师的Python数据清洗实战入门课程中的 csv文件读写小节, 巩固相关知识点
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^