各位谁帮我看看这错咋改啊
-- (5)创建课程表(course)
CREATE TABLE course(
cid CHAR(10) PRIMARY KEY AUTO_INCREMENT NOT NULL,
cname VARCHAR(20) NOT NULL,
ctype ENUM('基础课','专业基础课','专业课'),
credit DECIMAL(5,1) NOT NULL
)
> 1063 - Incorrect column specifier for column 'cid'
既然cid是自动递增,那么怎么能是char呢
CREATE TABLE course(
cid INT PRIMARY KEY AUTO_INCREMENT NOT NULL,
cname VARCHAR(20) NOT NULL,
ctype ENUM('基础课','专业基础课','专业课'),
credit DECIMAL(5,1) NOT NULL
);

要么去掉自动递增 要么 改类型不知道你这个问题是否已经解决, 如果还没有解决的话:
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7532034
- 这篇博客也不错, 你可以看下数据库定义及简单操作
- 除此之外, 这篇博客: 索引为什么这么快?中的 索引的实现 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
在没有索引的情况下,我们查找数据只能按照从头到尾的顺序逐行查找,每查找一行数据,意味着我们要到到磁盘相应的位置去读取一条数据。
如果把查询一条数据分为到磁盘中查询和比对查询条件两步的话,到磁盘中查询的时间会远远大于比对查询条件的时间,这意味着在一次查询中,磁盘io占用了大部分的时间。更进一步地说,一次查询的效率取绝于磁盘io的次数,如果我们能够在一次查询中尽可能地降低磁盘io的次数,那么我们就能加快查询的速度。
所以我们就要开始引入索引,然后分析索引底层是如何实现查找迅速的。
实际上索引的底层实际上就是树,也就 B 树和 B+ 树,也可以称之为变种的 B+ 树。大家也都知道 Mysql中最常用的引擎像InnoDB和MyISAM,最终都选择了B+树作为索引
那我们来说说这个B树和B+树。
B-树,也称为B树,是一种平衡的多叉树(可以对比一下平衡二叉查找树),它比较适用于对外查找
画一个二阶B树
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bQ9yTdaA-1635213867158)(http://www.justdojava.com/assets/images/2019/java/image_yi/07_20/1.jpg)]
那么我们为什么称他为二阶 B 树呢?这个阶数实际上就是说一个
节点最多有几个子节点我们上面的图,X元素,有2个子节点,A 元素,又有2个 子节点 C 和 D ,而 B 元素,又有 2 个子节点 E F ,也就是说一个节点最多有多少个子节点,我们就称它为几阶的树,通常这个值一般用 m 来表示。
注意我们所说的,也就是一个节点上 最多 的子节点数,如果有一个分支是有三个节点,而有一个是 两个节点 ,那我们就称它为 三阶 B 树。
一颗m阶的 B 树 要满足什么条件呢?
每个节点至多可以拥有m棵子树。
根节点,只有至少有2个节点(要么极端情况,就是一棵树就一个根节点,单细胞生物,即是根,也是叶,也是树)。
非根非叶的节点至少有的Ceil(m/2)个子树(Ceil表示向上取整,图中3阶B树,每个节点至少有2个子树,也就是至少有2个叉)。
非叶节点中的信息包括[n,A0,K1,A1,K2,A2,…,Kn,An],,其中n表示该节点中保存的关键字个数,K为关键字且Ki<Ki+1,A为指向子树根节点的指针。
从根到叶子的每一条路径都有相同的长度,也就是说,叶子节在相同的层,并且这些节点不带信息,实际上这些节点就表示找不到指定的值,也就是指向这些节点的指针为空。
B树的查询过程和二叉排序树比较类似,从根节点依次比较每个结点,因为每个节点中的关键字和左右子树都是有序的,所以只要比较节点中的关键字,或者沿着指针就能很快地找到指定的关键字,如果查找失败,则会返回叶子节点,即空指针。
B树搜索的简单伪算法如下:
BTree_Search(node, key) { if(node == null) return null; foreach(node.key) { if(node.key[i] == key) return node.data[i]; if(node.key[i] > key) return BTree_Search(point[i]->node); } return BTree_Search(point[i+1]->node); } data = BTree_Search(root, my_key);这就是个伪算法,写的不好,大家见谅,那么什么是 B+ 树呢?
B+ 树是一种树数据结构,是一个n叉树,每个节点通常有多个孩子,一颗B+树包含根节点、内部节点和叶子节点。根节点可能是一个叶子节点,也可能是一个包含两个或两个以上孩子节点的节点。
B+ 树通常用于数据库和操作系统的文件系统中。
NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。
B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。
B+ 树元素自底向上插入。
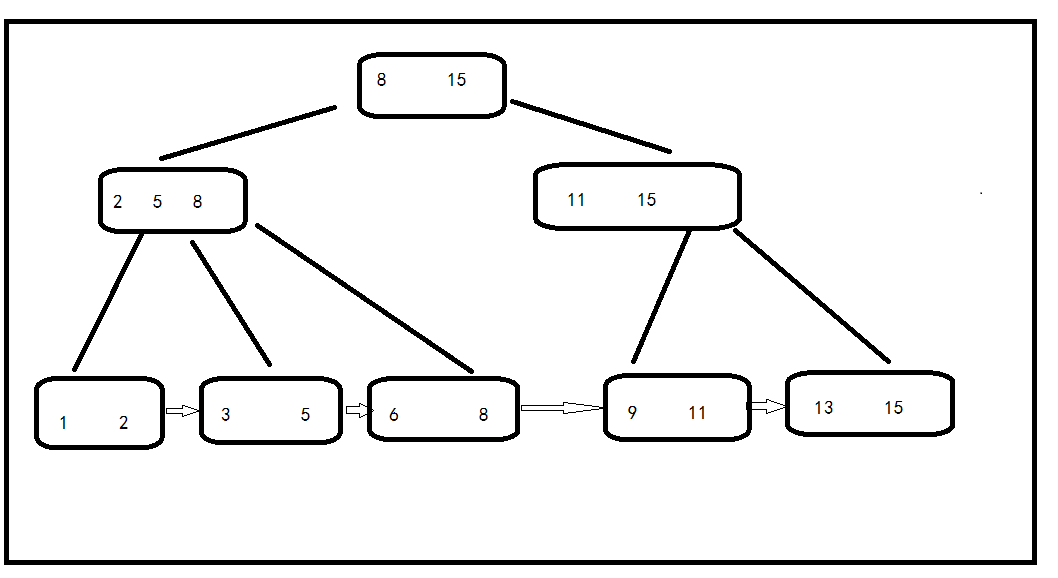
那 B+ 树又有哪些比较显著的特点呢?
每个父节点的元素都出现在了子节点中,分别是子节点最大或者最小的元素。
在上面的这一棵树中,根节点元素8是子节点258的最大的元素,根元素15也是。这时候要注意了,根节点最大的元素等同于整个B+树的最大的元素,以后无论是怎么插入或者是删除,始终都要保持最大的元素在根节点中。
叶子节点,因为父节点的元素都出现在了子节点当中,因此所有的叶子节点包含了全量的元素信息。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^