Python文本改写报错
环境:Python3.7,pycharm
问题:Python对文本进行读取,我想在文本的每一个段首和段尾各添加一个符号,但是尝试了更多方法均报错
请问有什么方式能够完成呢
可以使用 Python 的文件读写操作来实现。具体步骤如下:
打开文本文件,将文件内容读取到一个字符串中。
with open('file.txt', 'r') as f: content = f.read()这里使用了 Python 的
with语句,可以自动关闭文件,避免文件句柄泄漏等问题。对字符串进行处理,寻找每一段的起始和结束位置,并在对应位置添加符号。
symbol1 = '<' # 段首符号 symbol2 = '>' # 段尾符号 new_content = '' # 处理后的字符串 last_end = 0 # 上一段的结束位置 for match in re.finditer('\n\n+', content): start, end = match.span() new_content += content[last_end:start].strip() + symbol2 + '\n\n' + symbol1 last_end = end new_content += content[last_end:].strip() + symbol2具体来说,这里使用正则表达式
'\n\n+'来匹配段落的分隔符,然后处理每个匹配段落的起始和结束位置,最后在每一段的起始和结束位置添加对应的符号。将处理后的字符串写入新的文本文件。
with open('new_file.txt', 'w') as f: f.write(new_content)
完整的代码示例如下:
import re
symbol1 = '<' # 段首符号
symbol2 = '>' # 段尾符号
with open('file.txt', 'r') as f:
content = f.read()
new_content = ''
last_end = 0
for match in re.finditer('\n\n+', content):
start, end = match.span()
new_content += content[last_end:start].strip() + symbol2 + '\n\n' + symbol1
last_end = end
new_content += content[last_end:].strip() + symbol2
with open('new_file.txt', 'w') as f:
f.write(new_content)
注意,这里的代码仅处理以两个以上换行符作为段落分隔符的文本,不适用于其他形式的文本格式。如果需要处理其他格式的文本,可以根据实际情况调整正则表达式和处理逻辑。
start_symbol = '<'
end_symbol = '>'
with open('oldfile.txt', 'r',encoding='utf-8') as f:
content = f.readlines()
# print(content)
##建议用新文件命名(用同一个文件也可以),这样可以做对比;如果是空行就不做任何操作
with open('newfile.txt','w',encoding='utf-8') as wf:
for line in content:
if line.strip():
line = start_symbol + line.strip() + end_symbol
wf.write( line + '\n' )
else:
wf.write(line)
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7413008
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:python或pycharm处理中文时遇到问题解决方法
- 除此之外, 这篇博客: 怎么设置pycharm在创建.py文件时自动添加前缀(最全最详细的说明)中的 在运行pycharm进行python代码编写的时候,最好设置成自动添加前缀。这样既保护了自己的代码,也省去了很多编程环境不同带来的后续问题。 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
那么如何做呢???
首先打开pycharm,点击左上角文件下的设置。
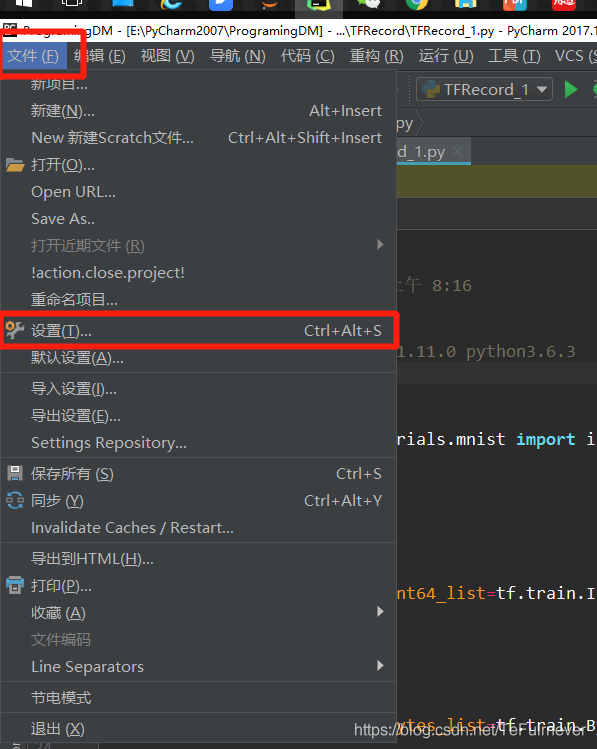
然后点击编辑器下的文件和代码模板中的Python Script。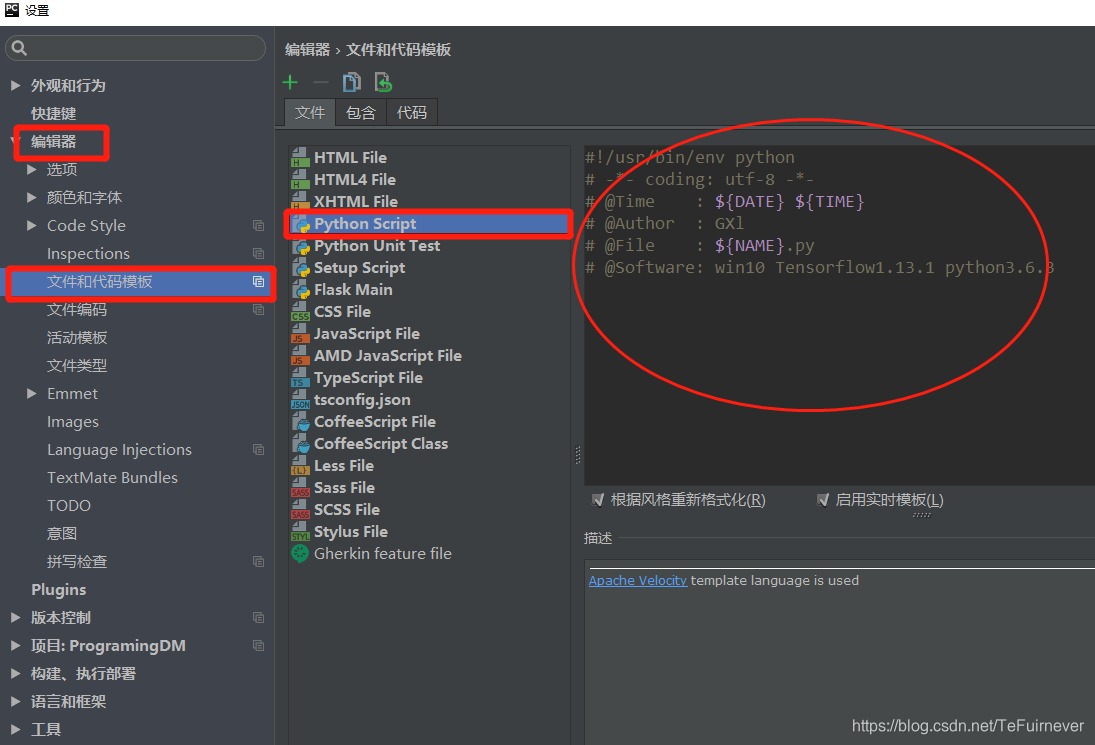
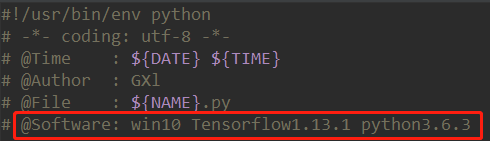
在红色圈圈的部分把你需要添加的前缀代码复制粘贴过去,一般比较常用的就是下面给出的这几个。#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : ${DATE} ${TIME} # @Author : GXl # @File : ${NAME}.py # @Software: win10 Tensorflow1.13.1 python3.6.3@Time系统会自动填写当前对应的日期和时间。
@File系统会自动填写当前对应的文件的名字。
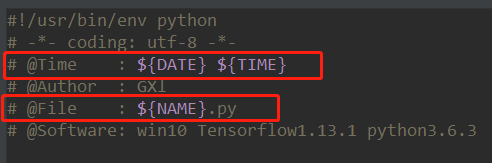
对应的==@Software==需要自己查询并填写。