R语言绘制火山图对数据使用case when函数报错
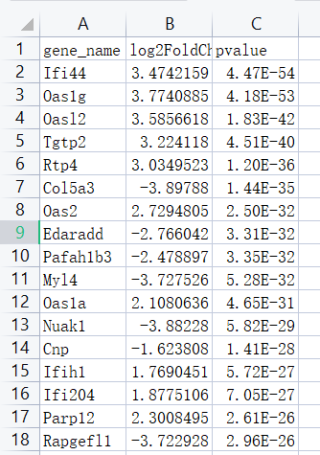
问题,绘制火山图时使用case when函数报错,读入文件格式如图,代码如下。请问报错原因是什么?是否是因为R语言并非最新版或是数据格式有误,数据仅包含gene name、log2FC、pvalue三列。如果需要补充信息请留意
> library(EnhancedVolcano)
> library(tidyverse)
── Attaching core tidyverse packages ────────────────────────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.1 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ lubridate 1.9.2 ✔ tibble 3.2.1
✔ purrr 1.0.1 ✔ tidyr 1.3.0
── Conflicts ──────────────────────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package to force all conflicts to become errors
Warning messages:
1: 程辑包‘tidyverse’是用R版本4.2.3 来建造的
2: 程辑包‘tibble’是用R版本4.2.3 来建造的
3: 程辑包‘tidyr’是用R版本4.2.3 来建造的
4: 程辑包‘readr’是用R版本4.2.3 来建造的
5: 程辑包‘purrr’是用R版本4.2.3 来建造的
6: 程辑包‘dplyr’是用R版本4.2.3 来建造的
7: 程辑包‘forcats’是用R版本4.2.3 来建造的
8: 程辑包‘lubridate’是用R版本4.2.3 来建造的
> df <- read.csv("volcano.csv", header = T,row.names = 1)
>group<-case_when(df$log2FoldChangeC<(-1)&df$pvalue<0.05 ~"#9AAFEF",
+ df$log2FoldChange>(1)&df$pvalue<0.05 ~"#EDB4B4",
+ df$pvalue >= 0.05 ~"#b5b5b5",
+ abs(df$log2FoldChange)<= 1 ~"#b5b5b5")
Error in `case_when()`:
! Can't recycle `..1 (left)` (size 0) to match `..2 (left)` (size 1271).
Run `rlang::last_trace()` to see where the error occurred.

引用chatGPT作答,这个错误信息的意思是不能将大小为0的对象“..1(left)”与大小为1271的对象“..2(left)”进行循环使用。很可能是由于您的case_when()函数中的某些条件未正确编写导致的。
请注意,在您的代码中有一处笔误,即:
df$log2FoldChangeC<(-1)
应该改为:
df$log2FoldChange<(-1)
这是一个可能导致错误的原因。如果您的数据框中没有“log2FoldChangeC”列,则这将导致无法找到该列并返回空值,从而导致向量大小为0。
另一个可能导致错误的原因是条件的逻辑错误。请确保您的条件表达式能够正确地评估所有行,并返回长度为1271的向量。
您可以尝试使用ifelse()函数来替换case_when()函数,并检查是否存在任何条件逻辑错误。
group <- ifelse(df$log2FoldChange < -1 & df$pvalue < 0.05, "#9AAFEF",
ifelse(df$log2FoldChange > 1 & df$pvalue < 0.05, "#EDB4B4",
ifelse(df$pvalue >= 0.05, "#b5b5b5",
ifelse(abs(df$log2FoldChange) <= 1, "#b5b5b5", NA))))
此外,建议您更新R版本以避免出现一些由版本不兼容性引起的问题。
你把源码和数据集发给我看一下
该错误通常出现在 dplyr 函数库的 case_when 函数中,提示无法对向量进行重复使用。
根据错误信息,可能存在的问题是,向量的长度不一致所导致的。具体来说,函数中使用的向量 df$1og2Fo1dChangeC 的长度为 0,与其他向量的长度不一致,导致了向量重复使用时的错误提示。
解决这个问题的方法有多种,具体方法取决于数据和分析的具体情况。以下是一些可能有用的建议:
检查向量的长度。确认向量的长度是否与预期一致。如果长度不一致,可以使用 length() 函数或其他函数进行调整。
确认向量的类型。确认向量的数据类型是否正确。例如,如果向量是字符向量,则需要用引号将其括起来。
检查语法错误。仔细检查代码中是否存在语法错误,例如括号、引号等的不匹配。
考虑使用其他函数。如果 case_when 函数无法正常工作,可以尝试使用其他函数,例如 ifelse() 或 switch() 等。
需要注意的是,这只是一些可能有用的建议,具体方法需要根据具体情况进行选择。在排查问题时,可以使用 rlang::last_trace() 函数来查看错误信息,以便更好地找到并解决问题。
以下内容部分参考ChatGPT模型:
这个错误是因为在使用case_when()函数时,条件不满足导致输出为空值,而空值无法进行循环使用,导致错误。可以使用if_else()函数来替代case_when()函数,避免出现空值。
下面是代码示例:
library(EnhancedVolcano)
library(tidyverse)
df <- read.csv("volcano.csv", header = T, row.names = 1)
group <- if_else(df$log2FoldChange < (-1) & df$pvalue < 0.05, "#9AAFEF",
if_else(df$log2FoldChange > 1 & df$pvalue < 0.05, "#EDB4B4",
if_else(df$pvalue >= 0.05, "#b5b5b5",
if_else(abs(df$log2FoldChange) <= 1, "#b5b5b5", NA_character_))))
在上述代码中,if_else()函数的使用方式与case_when()函数类似,但是当条件不满足时,输出为NA值,避免了空值的出现。
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
根据报错信息,问题出现在 case_when() 函数中,针对变量 df$log2FoldChangeC 的判断条件中,似乎此变量不存在或为空,导致无法正确计算。其中,左侧的 ..1 变量没有值(size 0),而右侧的 ..2 变量包含了 1271 个值(size 1271)。
这个问题可能有两个解决方案:
检查
df数据框中的列名,确认是否应该使用df$log2FoldChangeC而不是df$log2FoldChange,可能是输入文件有误导致的。检查
df数据框中是否有缺失值存在,如果有,则可以使用na.rm = TRUE参数将它们忽略,如:
group<-case_when(df$log2FoldChangeC<(-1)&df$pvalue<0.05 ~"#9AAFEF",
df$log2FoldChange>(1)&df$pvalue<0.05 ~"#EDB4B4",
df$pvalue >= 0.05 ~"#b5b5b5",
abs(df$log2FoldChange)<= 1 ~"#b5b5b5",
TRUE ~ "#000000", na.rm = TRUE)
在这个例子中,增加了一个 TRUE ~ "#000000" 的语句,为 data.frame 中其他未匹配到的行指定一个黑色(#000000)的替代颜色和绘制标准火山图的方法。
最后,检查一下是否使用了正确的 df$log2FoldChangeC 列名,并使用 rlang::last_trace() 函数来查看详细的出错信息,以帮助确定实际问题。
完整的代码如下:
library(EnhancedVolcano)
df <- read.csv("volcano.csv", header = TRUE, row.names = 1)
group <- case_when(df$log2FoldChangeC < (-1) & df$pvalue < 0.05 ~ "#9AAFEF",
df$log2FoldChange > 1 & df$pvalue < 0.05 ~ "#EDB4B4",
df$pvalue >= 0.05 ~ "#b5b5b5",
abs(df$log2FoldChange) <= 1 ~ "#b5b5b5",
TRUE ~ "#000000", na.rm = TRUE)
volcano(df, col = group)
希望能对您有所帮助!
如果我的回答解决了您的问题,请采纳!
根据报错信息,可以看到问题出在 case_when() 函数中,不能将两个向量进行递归。因此,需要检查一下输入数据的列名是否正确,是否有误。
在代码中,case_when() 函数中涉及到 df$log2FoldChangeC 列,但是前面读入的数据中并没有这一列,应该是 df$log2FoldChange 列,已经加了后缀 C 的错误。因此需要将代码中的 df$log2FoldChangeC 修改为 df$log2FoldChange 后再次运行,代码如下:
R
library(EnhancedVolcano)
library(tidyverse)
df <- read.csv("volcano.csv", header = T, row.names = 1)
group <- case_when(df$log2FoldChange < (-1) & df$pvalue < 0.05 ~ "#9AAFEF",
df$log2FoldChange > 1 & df$pvalue < 0.05 ~ "#EDB4B4",
df$pvalue >= 0.05 ~ "#b5b5b5",
abs(df$log2FoldChange) <= 1 ~ "#b5b5b5")
这样就可以正常地运行了。