YOLOv5训练模型的大小问题
训练两个模型,两个模型的best.pt文件的大小差异很大,这是什么原因呢
之前训练出来的大小
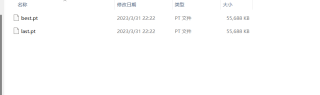
现在训练出来的大小
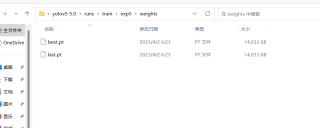
该回答通过自己思路及引用到各个渠道搜索综合及思考,得到内容具体如下:
训练出来的不同模型的best.pt文件大小差异很大可能有以下几个原因:
1、模型结构的不同。YOLOv5支持多个不同大小的模型,比如s、m、l、x等。不同的模型结构会导致最终训练出来的模型参数量不同,从而影响最终的模型文件大小。
2、训练数据集的不同。训练数据集的不同可能导致模型参数的数量不同,从而影响模型文件大小。
3、训练过程中的超参数设置不同。不同的超参数设置可能导致训练过程中模型参数的数量不同,从而影响模型文件大小。
4、优化器的不同。不同的优化器会对模型的训练过程产生不同的影响,从而可能导致最终训练出来的模型参数数量不同,进而影响模型文件大小。
5、训练的epoch数量不同。训练的epoch数量不同会导致模型参数的数量不同,从而影响模型文件大小。
总之,最终训练出来的YOLOv5模型文件大小与训练过程中的多个因素有关,而不仅仅是模型的准确率和性能。因此,对于具有相同功能的模型,它们的文件大小可能会有所不同,这并不一定意味着其中一个模型比另一个更好或更优秀。
如果以上回答对您有所帮助,点击一下采纳该答案~谢谢
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7769990
- 这篇博客你也可以参考下:基于yolov5的智能分类垃圾桶整套实现
- 除此之外, 这篇博客: YOLOv5训练自己的数据集中的 六、划分训练集和测试集 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
训练时要有测试集和训练集,放在ImageSets\Main文件夹下。代码如下,至于训练验证集和测试集的划分比例,以及训练集和验证集的划分比例,根据自己的数据情况决定。使用下面的代码进行划分:
import os import random xmlfilepath = 'D:\pycharm/yolov5/VOCdata/VOCTest/Annotations/' # xml文件的路径 saveBasePath = 'D:\pycharm/yolov5/VOCdata/VOCTest/ImageSets/' # 生成的txt文件的保存路径 trainval_percent = 0.9 # 训练验证集占整个数据集的比重(划分训练集和测试验证集) train_percent = 0.8 # 训练集占整个训练验证集的比重(划分训练集和验证集) total_xml = os.listdir(xmlfilepath) num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) train = random.sample(trainval, tr) print("train and val size", tv) print("traub suze", tr) ftrainval = open(os.path.join(saveBasePath, 'Main/trainval.txt'), 'w') ftest = open(os.path.join(saveBasePath, 'Main/test.txt'), 'w') ftrain = open(os.path.join(saveBasePath, 'Main/train.txt'), 'w') fval = open(os.path.join(saveBasePath, 'Main/val.txt'), 'w') for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close()运行后,得到ImageSets\Main\文件下的几个.txt文件。
数据集制作完成。
模型的大小与模型结构、超参数、训练数据集和训练方式等有关。
如果两个模型具有不同的架构(例如,它们使用的卷积层数量或通道数不同),则它们的大小可能不同。此外,如果两个模型的超参数设置不同(例如,学习率、权重衰减系数等),则可能会导致它们的大小不同。
另外,参与训练的数据集也可能是一个因素。如果两个模型所处理的数据集中图像的分辨率或数量不同,则可能会影响最终生成的模型文件的大小。还有,训练过程中使用的技术也可能对模型大小产生影响,如是否使用剪枝、量化等方法。
因此,在比较两个模型时,需要考虑多种因素,并仔细检查其相应的配置和训练日志,以确定原因并进行必要的调整。