如何用Python开发一个小型计算器
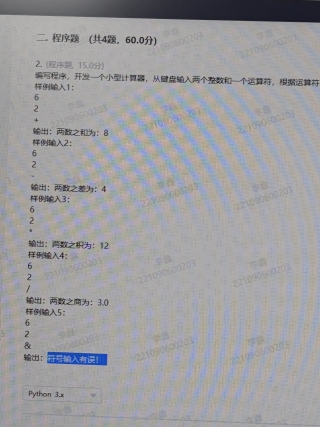
编写程序,开发一个小型计算器,从键盘输入两个整数和一个运算符
a = input()
b = input()
c = input()
print(eval(a+c+b))
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/390227
- 这篇博客你也可以参考下:当你用Python爬取网站遇到反爬,你应该这样做,轻松解决反爬问题
- 除此之外, 这篇博客: 用Python制作一个数据预处理小工具,多种操作,一键完成,非常实用!中的 重复值处理 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
对于二维列表DataFrame来讲使用
Pandas模块是最方便最象征办公简洁化的模块import pandas as pd df = df.read_excel('文件绝对路径') imfor = df[df.duplicated()] imfor = str(imfor)首先调用
Pandas模块并读取文件路径,这里我们采取绝对路径而不采取相对路径的原因是我们之后打包的GUI是不依靠文件的靠Python自带的环境,所以相对路径读取是无法识别的。df[df.duplicated()]这个Pandas内的函数是以二维列表形式来打印重复值对应的行。这里把df变量变为str字符串形式是因为我们在后来GUI中使用弹出窗口的元素时要以字符串形式加载。最终处理重复值的方法如下:
df = df.drop_duplicates(inplace = True)代码只有一行,却能做到将整个数据表中的重复值都删除,说明
Pandas函数的强大。至于为什么用inplace = True,是因为删除函数不并不能改变原表格结构,所以需要将新表覆盖原来的表格。
- 您还可以看一下 CSDN就业班老师的Python爬虫技术和浏览器模拟,验证码识别视频教程课程中的 网络爬虫阶段案例实战2小节, 巩固相关知识点