强化学习中遇到一些问题
强化学习是通过什么来控制多个物体的,是在编写环境的时候控制的吗,比如我图里,上下各六个教室,里面的学生出来走到出口,要怎么才能同时控制多个物体的移动并收集他们的数据。

- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/737173
- 这篇博客也不错, 你可以看下用命题逻辑推理的方法解决逻辑推理问题。 根据下面的命题,试用逻辑推理方法确定谁是作案者,写出推理过程。
- 除此之外, 这篇博客: 【论文阅读】深度学习与多种机器学习方法在不同的药物发现数据集进行对比中的 一、简介 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
药物发现目前正处于这样一个阶段:PubChem、ChEMBL以及越来越多由高通量筛选和高通量生物学(包括全细胞表型筛选、酶、受体等)创建的其他数据库的公共数据量不断增加,使其完全处于“大数据”领域。我们面临着重大的挑战。我们不再局限于少数分子及其性质,我们现在有成千上万的分子和几十个性质要考虑。我们如何挖掘、使用这些数据,并希望从中学习,从而使药物发现更有效、更成功?
一个方法是利用化学信息使用机器学习处理这些大数据的方法,如使用支持向量机(SVM), K近邻(KNN),朴素贝叶斯,决策树等已越来越多地使用。这些方法可以用于二进制分类、多类分类,或值的预测。
近年来,深度人工神经网络(包括卷积网络和递归网络)在模式识别和机器学习领域赢得了众多的竞争。深度学习通过引入以其他更简单的表示形式表示的表示来解决表示学习中的核心问题。n层神经网络如图1所示。
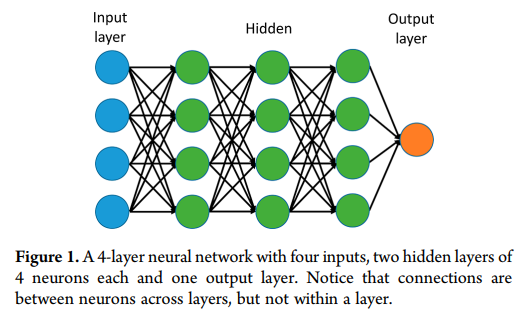
值得注意的是,单层神经网络描述的是一个没有隐含层的网络,其中输入直接映射到输出层。在这个意义上,逻辑回归或支持向量机只是单层神经网络的一个特例。在我们的工作中,为了简化深度神经网络(DNN)的表示,我们将只计算隐藏层。通常1−2隐藏层神经网络被称为浅神经网络和3或更多的隐藏层神经网络被称为深层神经网络。最近的一篇综述讨论了深度学习在药物研究中的发展和应用,这种方法在其他地方的图像和语言学习中被证明是非常成功的。以前深度学习主要用于无监督学习和噪声数据。将深度学习用于药物应用的有限努力表明,与其他方法相比,需要进一步探索其在化学信息学方面的效用。
深度学习在生物信息学和计算生物学中得到了较为广泛的应用。深度学习也被用于预测性质,如水溶性,使用四个公布的数据集,并与其他机器学习方法比较显示出良好的10倍交叉验证(10-fold cross validation)结果。
到目前为止,Merck已经对深层神经网络进行了比较,并将其与随机森林进行了比较,以使用大型定量结构活动关系(QSAR)数据集。他们发现在15个数据集中的11个表现要好于随机森林,在第二次使用时间分割测试集的评估中,15个数据集中的13个表现优于随机森林。但是Merck没有研究其他的机器学习方法。与其他机器学习方法一样,深度学习模型得到验证的最大例子之一是Tox21挑战。在核受体和应激反应数据集上,多任务学习的深度学习略优于最接近共识的ANN方法。最近,有一个小组提出了一些分子机器学习的数据集,并将这些数据集与选定的机器学习方法进行了比较。第二组用7个ChEMBL数据集评价了若干机器学习方法,但只着重于评价性能的单一指标。深度学习常常单独应用于单个数据集,而不是与许多可用的替代方法进行比较。有可能有更多的数据集可以从深度学习中受益,尽管它们可能更小。
这些机器学习方法越来越多地用于化合物的虚拟筛选,通过用活性化合物丰富筛选的化合物集,可以更有效地利用高通量筛选(,HTS)资源。此外,这种机器学习方法还可以用于药物的吸收、分布、代谢、排泄和毒性(ADME/Tox)特性,因为这些因素可以影响药物发现过程的成功,并且它们的早期评估可以预防失败。过去的研究表明这些计算方法可以极大地影响药物发现效率。
在过去的十年中,我们和其他人越来越关注贝叶斯方法,因为它们的易用性和一般适用性,使用最大直径6的分子函数类指纹和其他几个简单的描述符。这项工作的大部分集中在考虑细胞毒性的结核分枝杆菌模型上,并对其进行前瞻性评估,以显示与随机筛查相比,结核分枝杆菌的高命中率。此后,我们利用查加斯病和埃博拉病毒的数据集,对批准的药物以及模型ADME特性(如水溶性、小鼠肝微粒体稳定性、Caco-2细胞通透性、62个毒理学数据集和转运体)进行了重新利用。通过制作指纹,以及贝叶斯模型构建算法的开源,有潜力进一步拓展这方面的工作。
本研究的主要目的是 评估在药物发现和ADME/Tox数据集的其他计算方法中,使用一系列指标进行评估时,深度学习是否对测试有任何改善。在此过程中,我们开发了一种方法,使深度学习模型更容易获取。
- 您还可以看一下 AI100讲师老师的朋友圈爆款背后的计算机视觉技术与应用课程中的 朋友圈爆款背后的计算机视觉技术与应用小节, 巩固相关知识点
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^