目标检测二次检测应该如何实现
如何将两个目标检测模型合在一起呢,比如目的是要检测车牌,但由于交通场景里的车牌是小目标物,所以先检测出车辆,然后把车辆的目标框剪出来再输入到下一个网络当中去检测车牌
不知道你这个问题是否已经解决, 如果还没有解决的话:- 你可以看下这个问题的回答https://ask.csdn.net/questions/704211
- 你也可以参考下这篇文章:关于备案问题 免费帮您解决备案问题 该网站暂时无法访问 尊敬的用户,您好很抱歉,该网站暂时无法访问,可能由以下原因导致: 原因一:未备案或未接入;根据《非经营性互联网信息服务备案管理办法》,网站需要完
- 除此之外, 这篇博客: 单目测距终于摆脱了参考物,实现单目测距、检测物体大小,增加了实验数据,效果很好中的 📕传统方法 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
- 🍊其实单目摄像头的模型可以近似考虑为针孔模型,像下面这种:
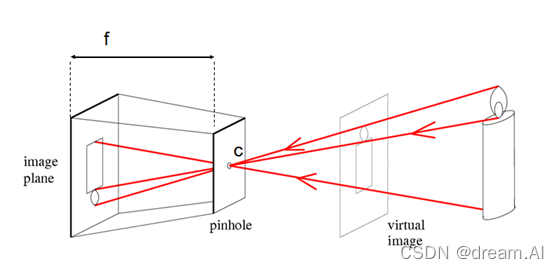
❤️其中
f是焦距
❤️C是镜头光心- 🍊物体通过镜头光心映射在图像传感器(像平面)上,像平面上会出现一个倒立的图像,通过对实际物体的测量,我们可以得到实际物体的高度,最后通过数学推算即可得到关于距离
D的一个数学公式,在这里就给各位读者大大手推一下: - 🍊字写的有点丑,望各位不要嫌弃。如有我没说明白之处,请大方指出,我会非常感谢您! ❤️

- 🍊上图就是前面针孔模型的一个手画版,只不过我把这些参数都标注了出来,方便自己给各位看官理解。
- 🍊在这里通过相似三角形可以推出下面这些数学公式,得到了最终的所求距离D和实际物体半径R的关系式,❤️在这里就可以看出来,我们必须得要清楚的知道实际物体的半径R才可以求出距离
D,若不知道R的大小,则就求不出距离D,而刚好这两个参数都是我需要去求解的东西❤️,当时我就卡在了这里,不知道该如何下手了;后面通过和朋友的沟通学习,我们找出来了第二种方法🎉。
- 🍊其实单目摄像头的模型可以近似考虑为针孔模型,像下面这种:
- 您还可以看一下 AI100讲师老师的朋友圈爆款背后的计算机视觉技术与应用课程中的 朋友圈爆款背后的计算机视觉技术与应用小节, 巩固相关知识点
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
将两个目标检测模型合并起来,可以采用以下步骤:
第一步是使用车辆检测模型,对输入图像进行车辆检测,得到车辆的目标框。可以使用基于深度学习的目标检测算法,如Faster R-CNN、YOLO或SSD等。
第二步是从原图像中剪裁出车辆目标框,并将其输入到车牌检测模型中进行车牌检测。车牌检测模型可以使用与车辆检测模型相同或不同的算法,根据实际情况选择。
第三步是将车辆和车牌的检测结果进行合并。可以使用简单的方法,如将车牌目标框的坐标加上车辆目标框的坐标,得到车牌在原图像中的坐标。也可以使用更加复杂的算法,如基于目标跟踪的方法,来对车辆和车牌的检测结果进行关联。
需要注意的是,合并两个目标检测模型时,需要考虑两个模型的检测精度和速度,以及模型之间的数据传输和处理效率等因素,以确保整个系统的性能和稳定性。