数据预处理,插值问题
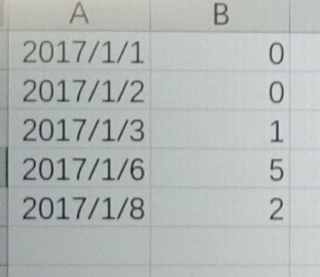
有没有办法利用python编码,pandas数据库实现时间连续的插值
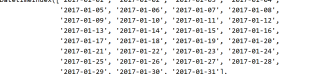
当然可以。你可以使用pandas中的date_range 生成连续的日期:
import pandas as pd
head_range = pd.date_range(start='2017-01-01',end='2017-01-31')
print(head_range)
- 你可以看下这个问题的回答https://ask.csdn.net/questions/185768
- 你也可以参考下这篇文章:pandas 异常值处理
- 除此之外, 这篇博客: 数据科学必备Python使用Pandas数据处理技巧中的 缺失值的运算 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
当进行求和运算时,缺失的数据将会被当作零来计算。如果数据全部为NA,那么结果也会返回NA。像 cumsum 和 cumprod 等方法回忽略NA值,但是会在返回的结果数组中回显示缺失的值。
df3 one two three a NaN -0.367818 0.731074 c NaN -1.837256 0.235959 e -0.096963 -0.608573 -0.321498 f -0.630936 0.498058 0.715187 h NaN -0.873389 1.138654 df3['one'].sum() -0.7278992566416747 df3.mean(1) a 0.181628 c -0.800649 e -0.342345 f 0.194103 h 0.132633 dtype: float64 df3.cumsum() one two three a NaN -0.367818 0.731074 c NaN -2.205073 0.967032 e -0.096963 -2.813647 0.645535 f -0.727899 -2.315588 1.360722 h NaN -3.188978 2.499376GroupBy中的NA值,在GroupBy中NA值会被直接忽略,这点同R相同。
df3.groupby('one').mean() two three one -0.630936 0.498058 0.715187 -0.096963 -0.608573 -0.321498