关于#pandas#的问题,如何解决?
使用pandas引用CSV文件报错
PS C:\Users\Eip_N\Downloads\k_means-master> & D:/Python37/python.exe c:/Users/Eip_N/Downloads/k_means-master/k_means-master/src/run.py
Traceback (most recent call last):
File "c:/Users/Eip_N/Downloads/k_means-master/k_means-master/src/run.py", line 37, in <module>
main(input_fn, output_fn, args.clusters)
File "c:/Users/Eip_N/Downloads/k_means-master/k_means-master/src/run.py", line 13, in main
df = pd.read_csv(dataset_fn)
File "D:\Python37\lib\site-packages\pandas\io\parsers.py", line 688, in read_csv
return _read(filepath_or_buffer, kwds)
File "D:\Python37\lib\site-packages\pandas\io\parsers.py", line 454, in _read
parser = TextFileReader(fp_or_buf, **kwds)
File "D:\Python37\lib\site-packages\pandas\io\parsers.py", line 948, in __init__
self._make_engine(self.engine)
File "D:\Python37\lib\site-packages\pandas\io\parsers.py", line 1180, in _make_engine
self._engine = CParserWrapper(self.f, **self.options)
File "D:\Python37\lib\site-packages\pandas\io\parsers.py", line 2010, in __init__
self._reader = parsers.TextReader(src, **kwds)
File "pandas\_libs\parsers.pyx", line 382, in pandas._libs.parsers.TextReader.__cinit__
File "pandas\_libs\parsers.pyx", line 674, in pandas._libs.parsers.TextReader._setup_parser_source
FileNotFoundError: [Errno 2] No such file or directory: 'data\\NYC_Free_Public_WiFi_03292017.csv'
源代码:
import os
import argparse
import pandas as pd
import sys, os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from src.clustering import KMeans
from src.point import Point
def main(dataset_fn, output_fn, clusters_no):
geo_locs = []
# read location data from csv file and store each location as a Point(latit,longit) object
df = pd.read_csv(dataset_fn)
for index, row in df.iterrows():
loc_ = Point(float(row['LAT']), float(row['LON'])) #tuples for location
geo_locs.append(loc_)
# run k_means clustering
model = KMeans(geo_locs, clusters_no)
flag = model.fit(True)
if flag == -1:
print("No of points are less than cluster number!")
else:
# save clustering results is a list of lists where each list represents one cluster
model.save(output_fn)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Run k-means for location data",
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--input', type=str, default='NYC_Free_Public_WiFi_03292017.csv',
dest='input', help='input location file name')
parser.add_argument('--output', type=str, default='output.csv', dest='output',
help='clusters output file name')
parser.add_argument('--clusters', type=int, default=8, dest='clusters', help='number of clusters')
args = parser.parse_args()
input_fn = os.path.join("data", args.input)
output_fn = args.output
main(input_fn, output_fn, args.clusters)
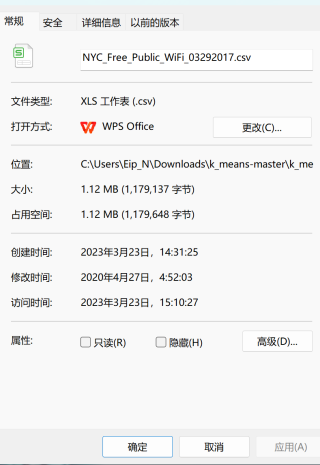
'data\\NYC_Free_Public_WiFi_03292017.csv'
目测data后面多了 \
- 这篇文章:pandas赋值失败问题解决 也许有你想要的答案,你可以看看