Oracle数据库提取时剔除重复10次的数据
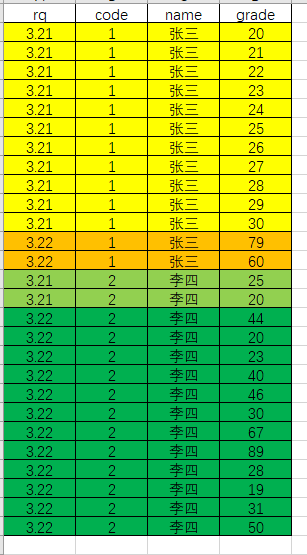
如上图,这是一个数据库原有的形式
现需要按照一定规则提取数据,规则如下
如果同时满足rq,code,name完全相等且相等条数大于10条,则提取时排除这些数据行
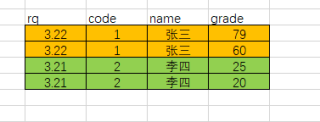
提取结果如下图所示,问如何实现
1、使用 count over,(注意你实际上的条件是 cnt < 10,我的测试数据少,用的是3)
WITH t0 AS (
SELECT '3.21' rq, 1 CODE, '张三' NAME, 20 grade FROM dual UNION ALL
SELECT '3.21' rq, 1 CODE, '张三' NAME, 21 grade FROM dual UNION ALL
SELECT '3.21' rq, 1 CODE, '张三' NAME, 22 grade FROM dual UNION ALL
SELECT '3.22' rq, 1 CODE, '张三' NAME, 23 grade FROM dual )
t1 AS (
SELECT t0.*, COUNT( 1 ) OVER( PARTITION BY rq, CODE, NAME ) AS cnt FROM t0 )
SELECT rq, CODE, NAME, grade FROM t1 WHERE cnt < 3;
2、使用 group by
WITH t0 AS (
SELECT '3.21' rq, 1 CODE, '张三' NAME, 20 grade FROM dual UNION ALL
SELECT '3.21' rq, 1 CODE, '张三' NAME, 21 grade FROM dual UNION ALL
SELECT '3.21' rq, 1 CODE, '张三' NAME, 22 grade FROM dual UNION ALL
SELECT '3.22' rq, 1 CODE, '张三' NAME, 23 grade FROM dual )
, t1 AS (
SELECT DISTINCT rq, CODE, NAME FROM t0 GROUP BY rq, CODE, NAME HAVING COUNT( 1 ) < 10 )
SELECT * FROM t0 JOIN t1 ON t0.rq = t1.rq AND t0.code = t1.code AND t0.name = t1.name;
那你先写个子查询,count,group by一下,先查询重复10次以上的数据
然后原始数据写个not in,排除掉这些数据
select * from table where ( rq,code,name)in ( select rq,code,name from table group by rq,code,name having count(1)<10);