python多进程耗时问题
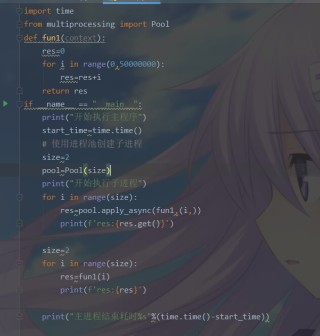
主函数里分别是多进程和单进程的代码,但是我分别运行发现两个时间几乎没差别呀,甚至多进程的还慢了一秒左右,请问问题出在哪里呢
你这里并没有真正的调用到多进程执行程序,
当你调用多进程执行的时候,实际上程序是阻塞执行的,并没有并行执行
def func1():
res = 0
for i in range(1, 50000000):
res+=i
return res
if __name__ == '__main__':
print("开始执行程序")
start_time = time.time()
size = 2
pool = Pool(2)
for i in range(size):
print("输出这里,查看是阻塞执行的程序")
res = pool.apply_async(func1)
print(f'res:{res.get()}')
end_time = time.time()
print(end_time-start_time)
程序本身运行耗时比较小,所以额外开销不能忽略不计
启动进程是要消耗时间的
而你循环次数太少,直接执行反而快
你在循环里加个sleep再看呢?
该回答引用GPTᴼᴾᴱᴺᴬᴵ
可能是因为在这个代码中执行的任务非常简单,只是一个简单的计算循环,导致多进程的额外开销和通信消耗占用了更多的时间,从而得不到显著的性能提升。
·
多进程的优势在于处理大量数据或者需要复杂计算的任务时会更为明显。如果你想测试多进程的性能优势,可以尝试使用更加耗时的任务,比如涉及到磁盘读写或者网络通信的任务。同时也可以尝试调整进程池的大小,看看在不同的进程数下性能变化情况。
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7740210