Python的正则怎么写可以从很长的字符串中提取想要的内容并按行存入列表
如图所示的str,我想要从中提取出划灰色线部分的内容(1.去掉红色箭头所指向的-a/-c以及后面的内容;2.去掉如local/master/xlty/adve参数;3.去掉前面的数字以及数字前的字符)
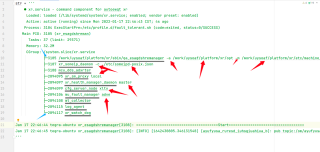
如果以数字前的特殊字符(就是蓝色箭头指的部分)来匹配,忽略掉特殊字符后的数字和一个空格,拿到画灰色线的部分,然后再一个空格,忽略掉后面的local/xlty/-c,然后提取下一行的灰色线内容(从3105~2094117),那么我的正则表达式该如何写
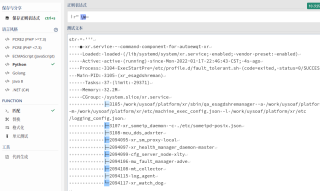
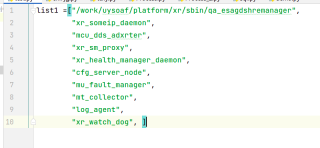
最后我想得到这样的一个列表
str = '''
● xr.service - command component for autoewqt xr
Loaded: loaded (/lib/systemd/system/xr.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-01-17 22:46:43 CST; 4s ago
Process: 3104 ExecStartPre=/etc/profile.d/fault_tolerant.sh (code=exited, status=0/SUCCESS)
Main PID: 3105 (xr_esagdshreman)
Tasks: 37 (limit: 29371)
Memory: 32.2M
CGroup: /system.slice/xr.service
├─3105 /work/uysoaf/platform/xr/sbin/qa_esagdshremanager -a /work/uysoaf/platform/xr/opt -m /work/uysoaf/platform/xr/etc/machine_exec_config.json -l /work/uysoaf/platform/xr/etc/logging_config.json
├─3107 xr_someip_daemon -c ./etc/someipd-posix.json
├─3108 mcu_dds_adxrter
├─2094095 xr_sm_proxy local
├─2094097 xr_health_manager_daemon master
├─2094099 cfg_server_node xlty
├─2094106 mu_fault_manager adve
├─2094108 mt_collector
├─2094115 log_agent
└─2094117 xr_watch_dog
Jan 17 22:46:44 tegra-ubuntu xr_esagdshremanager[3108]: [INFO] [1642430804.345211908] [ayufyusa_ruresd_iuhsgiuahiua_b]: sub topic:/om/fault_collect is online in node:/ayufyusa_ruresd_iuhsgiuahiua_b
Jan 17 22:46:44 tegra-ubuntu xr_esagdshremanager[3108]: ======================================Start===================================
Jan 17 22:46:45 tegra-ubuntu xr_esagdshremanager[3108]: [INFO] [1642430805.346131548] [ayufyusa_ruresd_iuhsgiuahiua_b]: pub topic:/om/ayufyusab_fault_report is online in node:/faultclient_mcu_dds_adxrter
'''
能把str的内容贴出来吗
把你的文本贴上来啊。。。你这样让人自己写测试文本太麻烦了
(?=.*?[━┗┣]\d+ ([^\s]+))[^\r\n]+
先把片段分开
(?=.*?[━┗┣]\d+ ([^\s]+)) 在当前位置匹配后边有制表符跟数字的位置后,取连续非空格内容,结合下边的限制,一行只取一个内容
[^\r\n]+ 限定为一行内容
[━┗┣]\d+ (.*?)[ \r\n]
匹配到制表符跟数字,取这个位置后连续非空格回车换行的内容
----------------
[] 限制匹配的字符集 [━┗┣] 就是限制为三个制表符中任意一个的匹配
\d 就是数字 + 是长度修饰,至少匹配一个,可以匹配多个
() 就是分组,在python 正则中,如果没有分组,则返回匹配成功的内容,如果有分组,则一个分组时返回分组内的内容,多个分组,按元组方式返回
\r 回车 \n 换行 \s 空格
[^\s] 字符集定义中,^ 表示非的意思
思路是使用正则表达式,记得允许下多行匹配。
参考GPT和自己的思路,以下是实现你需求的代码,有任何疑问请回复我:
import re
data = """process: 3104 exec
CGroup:system.slice/xr.service
3105 /work/uysoaf/platform/xr/sbin/qa_esagdshremanager
3107 xr_someip_daemon
3108 mcu_dds_adxrter
2094095 xr_sm_proxy
2094097 xr_health_manager_daemon
2094099 cfg_server_node
2094106 mu_fault_manager
2094108 mt_collector
2094115 log_agent
2094117 xr_watch_dog"""
lines = data.split("\n")
list1 = []
cgroup_line = None
for i, line in enumerate(lines):
if "CGroup" in line:
cgroup_line = i
break
if cgroup_line is not None:
for line in lines[cgroup_line+1:]:
match = re.search("^\d+ .*?", line)
if match:
parts = line.split()
list1.append(" ".join(parts[1:]))
print(list1)
在这个代码中,首先找到包含CGroup的那一行,并记录其行数。然后,在该行之后遍历所有行,并查找以数字开头的行。最后,将找到的每一行的第一个单词之后的部分添加到列表中。