C++从文件读200000个long long数据边读边插入multiset卡住
从文件流读200000个long long类型的数,一边读一遍插入multiset,但是读到199000左右程序总会卡住,但是等待90s左右程序会继续运行完毕。
我做了一些尝试:
- 注释掉ms.insert(),可以读完,不会卡住。这说明文件里面是有200000个数字的。
- 不从文件流读数据,随机生成200000个long long类型的数,边生成边insert到multiset,可以全部插入,不会卡住。
- 把n改小一些,边读边insert,还是会在比n略小的地方读取卡住。哪怕把n改到20000,也会在略小于n的地方卡住。
- 使用clock()计时,虽然在199000左右程序总会卡住,但是卡住的那组数据的计时的结果和其他的一样,都是0。
#include ms;
for(int i=0;i> inum;
ms.insert(inum);
}
ll cnt=0;
for(multiset::iterator it = ms.begin();it != ms.end();it++){
cnt += ms.count(*it+c);
}
cout << cnt;
return 0;
}
等待一会是可以读完的:
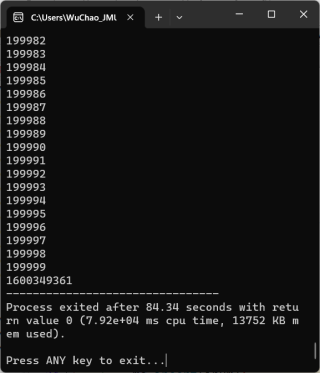
卡住的那条数据卡住的时间没有被clock记录下来
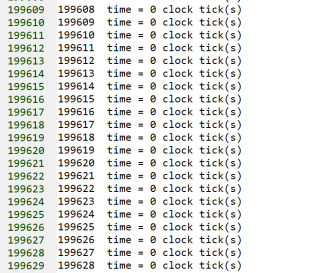
我测试了一下,没有问题啊。但是你这用multiset统计出现次数有点浪费了
参考GPT和自己的思路:这个问题可能与你的输入流有关。如果你的输入流从硬盘读取数据,速度可能会比从内存读取慢得多。multiset的插入操作具有O(log n)的时间复杂度,而从硬盘读取数据可能需要几毫秒的时间,这可能会导致在插入大量元素时程序卡住。
为了解决这个问题,你可以考虑使用一个缓冲区来存储从文件读取的数据,然后一次性地将所有数据插入multiset中。这样可以减少文件I/O操作的次数,并提高程序的性能。例如,你可以使用一个数组来存储从文件读取的数据,然后使用一个for循环将所有数据插入multiset中,如下所示:
#include <fstream>
#include <iostream>
#include <set>
using namespace std;
typedef long long ll;
const int MAXN = 200000;
ll a[MAXN];
int main(){
ifstream cin("20230303.txt");
ios::sync_with_stdio(false);
cin.tie(0),cout.tie(0);
ll n,c,inum;
cin >> n >> c;
multiset<ll> ms;
for(int i=0;i<n;i++){
cin >> a[i];
}
for(int i=0;i<n;i++){
ms.insert(a[i]);
}
ll cnt=0;
for(multiset<ll>::iterator it = ms.begin();it != ms.end();it++){
cnt += ms.count(*it+c);
}
cout << cnt;
return 0;
}
这个版本的代码使用了一个数组来存储从文件中读取的数据。然后,使用一个循环将所有数据插入multiset中。这个版本的代码避免了在插入过程中的文件I/O操作,因此应该比较快。
参考GPT和自己的思路,可能是由于内存不足导致的磁盘交换或磁盘读写问题。当您插入200000个long long类型的数到multiset中时,multiset需要分配大量的内存来存储这些数。如果您的计算机内存不足,操作系统会将一部分内存交换到磁盘上,这会导致程序运行缓慢,因为磁盘交换速度比内存慢得多。
在读取数据时,建议使用C++标准库中的快速读入方式,比如使用 scanf 函数代替 cin。因为 cin 在读取大量数据时比较慢,会有一定的性能瓶颈。
同时,在插入数据时,也可以优化一下,将读入的数据先存储到一个数组中,再对数组进行排序和去重,最后再插入到 multiset 中。这样可以避免 multiset 频繁的插入和查找操作,提高程序效率。
下面是优化后的代码:
#include <fstream>
#include <iostream>
#include <set>
#include <algorithm>
using namespace std;
typedef long long ll;
const int maxn = 200005;
ll a[maxn];
int main(){
ifstream cin("20230303.txt");
ios::sync_with_stdio(false);
cin.tie(0),cout.tie(0);
ll n,c,inum;
scanf("%lld %lld",&n,&c);
for(int i=0;i<n;i++){
scanf("%lld",&a[i]);
}
sort(a,a+n);
n = unique(a,a+n)-a;
multiset<ll> ms(a,a+n);
ll cnt=0;
for(multiset<ll>::iterator it = ms.begin();it != ms.end();it++){
cnt += ms.count(*it+c);
}
printf("%lld",cnt);
return 0;
}
这里将读入的数据存储在数组中,使用 sort 函数对数组进行排序,再使用 unique 函数去重,最后将去重后的数组作为参数传入 multiset 中,避免了 multiset 频繁的插入和查找操作。
另外,在输出结果时,可以使用 printf 函数代替 cout,因为 cout 在输出大量数据时也会有一定的性能瓶颈。