python 统计学习方法 分类问题
np.where((X[:,i] == ch_i) * (Y == c), w, 0.0)这句是什么意思呀?
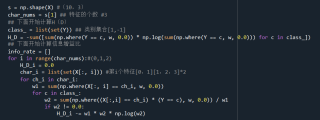
该回答引用gpt:
这是一个使用numpy库中的where函数的语句,其中X是一个二维的numpy数组,Y是一个一维的numpy数组,w是一个浮点数,ch_i和c是两个整数。
这句语句的作用是:如果X数组的第i列的元素等于ch_i,且Y数组的元素等于c,那么将w赋值给新的数组的相应位置,否则赋值为0。其中,新的数组是通过where函数生成的。
具体来说,where函数的用法是:np.where(condition, x, y),其中condition是一个bool型的numpy数组,x和y是两个相同形状的numpy数组,如果condition中对应的元素为True,则新的数组对应位置的元素为x中对应位置的元素,否则为y中对应位置的元素。
在这句语句中,condition的值是(X[:,i] == ch_i) * (Y == c),即X数组的第i列的元素等于ch_i且Y数组的元素等于c的位置为True,其余位置为False。因此,新的数组中只有这些True对应的位置的元素才会被赋值为w,其余位置的元素为0。
这段代码是用于分类问题中计算分类器的权重的,其中:
X 是输入的特征矩阵,其中每一行表示一个样本,每一列表示一个特征。
Y 是标签向量,表示每个样本的真实标签。
i 是一个整数,表示当前正在处理第 i 个特征。
ch_i 是一个特征可能的取值。
c 是一个类别。
代码中的 np.where() 函数用于在条件成立时返回 w,否则返回 0.0,其中条件为 (X[:,i] == ch_i) * (Y == c),表示第 i 列特征的值为 ch_i 并且标签为 c 的样本。这里的 * 是 numpy 数组的逐元素乘法,即对两个数组对应位置的元素进行相乘。
这段代码的作用是统计第 i 列特征的值为 ch_i 并且标签为 c 的样本的权重,用于更新分类器的参数。
- 建议你看下这篇博客👉 :机器学习python下数据分类方法