python爬虫位置问题
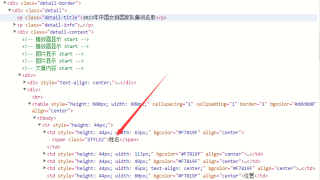
就是如果用beautifulsoup去爬每一个span里的内容的话,

这一块怎么写啊(当然如果愿意给全部代码,更感激不尽)
该回答引用GPTᴼᴾᴱᴺᴬᴵ
如果您想要提取 div class="detail-context"标签下所有的 tr 标签,并进一步提取每个 tr 中的 td 标签内的内容,可以使用以下代码:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
tr_list = soup.select('.detail-context tr')
for tr in tr_list:
td_list = tr.select('td')
name = td_list[0].text.strip()
position = td_list[-1].text.strip()
print(f'姓名:{name},位置:{position}')
在这个示例中,我们首先使用 requests 库获取页面的 HTML 内容,并使用 BeautifulSoup 对其进行解析。然后,我们使用 soup.select() 方法选取所有位于
标签下的 标签,并对其进行循环遍历。在每个 标签内部,我们使用 tr.select() 方法选取所有的 标签,并分别提取第一个和最后一个 标签内的文本内容,即球员的姓名和位置。最后,我们使用 print() 函数输出结果。
请注意,这只是一个示例,具体实现方式可能会因网页结构和内容的不同而略有差异。
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7766363
- 同时,你还可以查看手册:python- 位置或关键字参数 中的内容