随机森林特征重要性相关问题
在随机森林中,重要性高的特征是不是意味着在预测结果时被赋予了更大的权重呢?
- 这篇文章:随机森林模型详解 也许能够解决你的问题,你可以看下
- 除此之外, 这篇博客: 随机森林,随机森林中进行特征重要性中的 只要了解决策树的算法,那么随机森林是相当容易理解的。随机森林的算法可以用如下几个步骤概括: 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
- 用有抽样放回的方法(bootstrap)从样本集中选取n个样本作为一个训练集
- 用抽样得到的样本集生成一棵决策树。在生成的每一个结点:
- 随机不重复地选择d个特征
- 利用这d个特征分别对样本集进行划分,找到最佳的划分特征(可用基尼系数、增益率或者信息增益判别)
- 重复步骤1到步骤2共k次,k即为随机森林中决策树的个数。
- 用训练得到的随机森林对测试样本进行预测,并用票选法决定预测的结果。
下图比较直观地展示了随机森林算法(图片出自文献2)
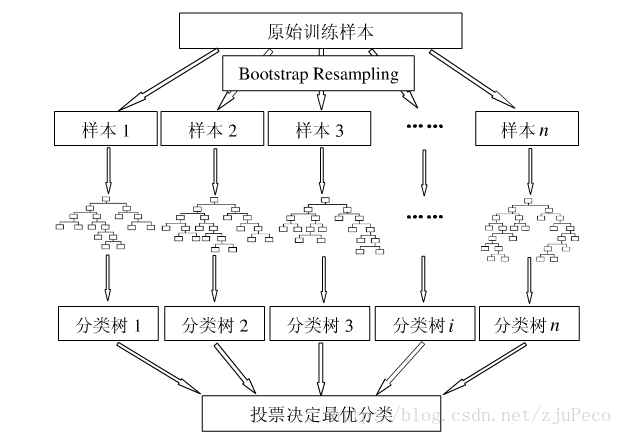
是在训练的时候赋予更大的权重,而不是预测,这个也是随机森林可以评估每个特征重要性的一个特点之一。
预测的时候,是他本身就会比其他特征的权重高,所以重要特征对于结果的影响大。
上面所说的权重高是指影响大小,而不是本身数值高低(拿0-1二分类举例来说,某个特征有出现就是负类,那么他的权重可能会是0,或者一个很大的负值,来将其他特征累积的权重拉到最低,就数值上来说并不是最大,但是从结果影响来说,这个权重是很高的)