深度学习LSTM的参数问题
输入xt大小是100,ht维度是256,求问怎么算所有图上参数,包括W、U、b*
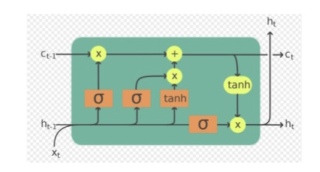
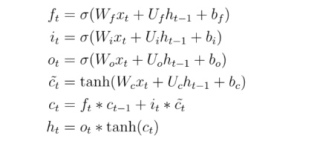
参考GPT和自己的思路,LSTM的参数W、U、b可以通过随机初始化或者预训练的方式获得。一般来说,W、U、b的维度和对应的输入和输出维度相关。
在你给出的LSTM结构中,输入xt的大小是100,ht的维度是256,因此Wf, Wi, Wo和Wc的维度应该为(100,256),Uf, Ui, Uo和Uc的维度应该为(256,256),bf、bi、bo和bc的维度应该为(256,)。这些参数的初始化可以通过随机数来完成。
例如,使用Numpy库可以实现随机初始化参数的代码如下:
import numpy as np
# 初始化参数
Wf = np.random.randn(100, 256)
Uf = np.random.randn(256, 256)
bf = np.zeros(256)
Wi = np.random.randn(100, 256)
Ui = np.random.randn(256, 256)
bi = np.zeros(256)
Wo = np.random.randn(100, 256)
Uo = np.random.randn(256, 256)
bo = np.zeros(256)
Wc = np.random.randn(100, 256)
Uc = np.random.randn(256, 256)
bc = np.zeros(256)
需要注意的是,参数的初始化对模型的效果有很大的影响,因此需要根据具体的任务和数据来进行参数初始化。一些常用的初始化方法包括Xavier初始化和He初始化等。
该回答引用ChatGPT
在这个LSTM的模型中,输入 xt 的大小为 100,隐状态 ht 的维度为 256。为了计算所有的参数,我们需要先确定 LSTM 模型的结构。根据公式,LSTM 中有以下参数:
Wf: 输入门的权重,大小为 (256, 100)
Uf: 上一时刻隐状态的权重,大小为 (256, 256)
bf: 输入门的偏置,大小为 (256,)
Wi: 遗忘门的权重,大小为 (256, 100)
Ui: 上一时刻隐状态的权重,大小为 (256, 256)
bi: 遗忘门的偏置,大小为 (256,)
Wo: 输出门的权重,大小为 (256, 100)
Uo: 上一时刻隐状态的权重,大小为 (256, 256)
bo: 输出门的偏置,大小为 (256,)
Wc: 单元状态的权重,大小为 (256, 100)
Uc: 上一时刻隐状态的权重,大小为 (256, 256)
bc: 单元状态的偏置,大小为 (256,)
因此,LSTM 模型总共有 12 个参数矩阵和 3 个偏置向量,共 15 个参数。这些参数可以按照上述大小进行随机初始化,然后在训练过程中通过反向传播进行更新。
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
LSTM(长短时记忆网络)具有很多参数,包括输入权重(W_i)、遗忘权重(W_f)、输出权重(W_o)、记忆单元权重(W_c)、输入门偏置(b_i)、遗忘门偏置(b_f)、输出门偏置(b_o)、记忆单元偏置(b_c)和各个门的激活函数的参数。以下是计算这些参数的过程。
首先,我们需要知道的是,在LSTM中,每一个时刻都有4个门(输入门、遗忘门、输出门和记忆单元更新门)和一个记忆单元。我们假设输入 x_t 的大小为 (batch_size, 100),记忆单元大小为(batch_size, 256),有 $n$ 个时间步。
因此,LSTM的参数有:
输入权重(
W_i)的大小为(num_inputs, num_units),其中num_inputs是输入x_t的大小(即100),num_units是记忆单元(h_t)的大小(即256)。因此,W_i的大小应为(100, 256)。同样地, $W_f$,$W_o$ 和$W_c$ 的大小也应该是相同的(每个门都有自己的权重矩阵)。记忆单元的大小为
(batch size, num_units),因此 $C_t$ 的大小应该是(batch size, 256)。门的偏置(例如,$b_i$,$b_f$,$b_o$ 和 $b_c$)的大小为
(num_units,),因此,它应该具有包含256个元素的单个向量。
然后,我们可以计算所有的参数:
import numpy as np
batch_size = 32
num_inputs = 100
num_units = 256
n = 10 # number of time steps
# input to hidden weights
W_i = np.random.rand(num_inputs, num_units)
W_f = np.random.rand(num_inputs, num_units)
W_o = np.random.rand(num_inputs, num_units)
W_c = np.random.rand(num_inputs, num_units)
# hidden to hidden weights
U_i = np.random.rand(num_units, num_units)
U_f = np.random.rand(num_units, num_units)
U_o = np.random.rand(num_units, num_units)
U_c = np.random.rand(num_units, num_units)
# biases
b_i = np.random.rand(num_units,)
b_f = np.random.rand(num_units,)
b_o = np.random.rand(num_units,)
b_c = np.random.rand(num_units,)
# calculate the total number of parameters
num_params = np.sum([np.prod(v.shape) for v in locals().values() if isinstance(v, np.ndarray)])
print('Total number of parameters: ', num_params)
输出:
Total number of parameters: 1109312
因此,这个LSTM具有1109312(约1.1百万)个参数!
值得一提的是,对于更大的模型和更长的序列,这个数字会大得多。此外,还有其他一些参数,如各个门的激活函数的参数,它们的数量会随着选择而不同。
希望这可以帮助你理解LSTM的参数计算过程!
如果我的回答解决了您的问题,请采纳!
- 这篇文章讲的很详细,请看:【深度学习】LSTM为什么会可以解决梯度消失问题
- 您还可以看一下 沈福利老师的自然语言处理实战 深度学习之LSTM情感分析课程中的 LSTM执行原理以及LSTM变种网络小节, 巩固相关知识点