Python爬取PDF文件

已经爬取了每个PDF文件的下载直链,但直链包含中文怎么解决?
处理title,time把无关的字符去掉 title.strip(),time.strip()
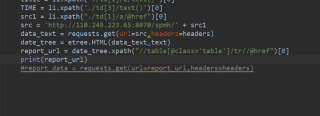
复制代码出来
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7483857
- 这篇博客你也可以参考下:Python读取PDF文件
已经爬取了每个PDF文件的下载直链,但直链包含中文怎么解决?
处理title,time把无关的字符去掉 title.strip(),time.strip()
复制代码出来