多分类任务的分类效果极差
读取csv文件并进行8分类
csv文件数据集如下:

最后一列为label:1-8,即8分类
尝试:dag-SCM/简单的深度学习nn
问题:如果不进行normalization,则完全不学习,分类效果极差,acc=10,结果如下图:
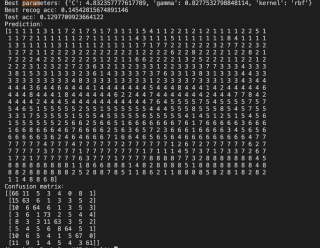
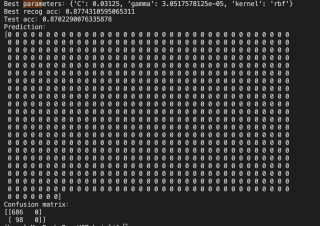
进行normalization,prediction为0,无标签,混淆矩阵如下
参考GPT和自己的思路,首先,您提到的csv文件似乎有一些格式问题。网络列之间似乎缺少空格或逗号分隔符,可能是由于剪切和粘贴时发生了错误。另外,您的第7列似乎也被拆分成了“network”和“8”的两个单词。如果您可以将数据格式化并重新发布,这将有助于更好地理解您的数据。
其次,您提到如果不进行数据标准化,分类效果很差,这是可以理解的。对于基于距离或相似度的算法(如SVM),如果不对输入数据进行标准化,则其中一些特征的值范围可能会远远大于其他特征。这将导致某些特征对距离度量的影响远大于其他特征,从而影响分类器的性能。
您提到尝试了两种算法:dag-SCM和简单的深度学习nn。无论您使用哪种算法,都应该在输入数据之前对其进行标准化。如果您使用的是深度学习算法,则通常会将数据标准化为均值为0,标准差为1的标准正态分布。如果您使用的是SVM等算法,则可以使用min-max标准化将所有特征缩放到0到1之间。
最后,关于您的混淆矩阵:如果分类器的预测结果与真实标签相差太远,那么混淆矩阵可能会变得非常不平衡。在这种情况下,精度不一定是最好的性能度量。您可以考虑使用其他度量,如F1分数或ROC曲线下面积(AUC),以更好地了解分类器的性能。
以下是使用Python中的pandas和scikit-learn库进行数据读取、归一化、训练和预测的示例代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, confusion_matrix
# 读取CSV文件
df = pd.read_csv('data.csv')
# 分割特征和标签
X = df.iloc[:, :-1]
y = df.iloc[:, -1]
# 将数据集分割成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 归一化特征数据
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 训练SVM分类器
clf = SVC(kernel='rbf', C=0.03125, gamma=3.0517578125e-05)
clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = clf.predict(X_test)
# 计算预测准确率和混淆矩阵
acc = accuracy_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
print('Test accuracy:', acc)
print('Confusion matrix:', cm)
请注意,上述示例代码中的SVM参数是使用GridSearchCV进行超参数优化后得到的最佳参数。您可以根据需要更改SVM的参数和超参数优化的方法。此外,如果您使用的是其他分类算法(例如神经网络),则需要相应地更改代码。
您好,关于您提出的问题,为您提供一些思路,希望能帮助到您:
1)在机器学习和深度学习中的分类,往往都是要进行normalization,这一步就不是少的
2)保证训练和测试数据的处理统一,训练时做了normalization,测试时也要做normalization,这一点很重要。
3)查输入的数据维度是否正确,训练和测试时要使用同样的数据维度顺序,现在好多分类模型在后面会添加AdaptiveAvgPool层,即使输入的数据尺寸和训练时不一样也不会报错
4)检查模型参数加载是否正确,在加载过程中,如果参数和模型不匹配会报错,但是会使用默认的随机参数。
5)由于您没有提供具体的处理方法,建议您从模型、模型参数、损失函数等各个地方逐一检查下。
1、检查模型训练和模型测试的数据处理pipeline是否一致,比如训练时做了Normalize,测试时也要做Normalize,这一点至关重要,我遇到的这类问题基本上都是因为数据预处理不一致导致的
2、检查模型在测试时有没有切换到推理模式,如pytorch中的eval()转换
3、检查输入的数据维度是否正确,比如训练时使用[N, C, H, W],测试时也要使用同样的数据维度顺序,现在好多分类模型在后面会添加AdaptiveAvgPool层,即使输入的数据尺寸和训练时不一样也不会报错
4、检查模型参数加载是否正确,还是以pytorch框架为例,pytorch在加载模型时如果设置完全匹配的参数为False,在加载过程中即使参数和模型不匹配也不会报错,但是会使用默认的随机参数
- 文章:异常的分类和处理机制 中也许有你想要的答案,请看下吧
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
首先,对于分类效果极差的问题,我们可以考虑以下几个方面:
数据质量问题:可能数据有噪声或者数据分布不均匀,可以通过观察数据分布和去除异常值等方法来处理数据质量问题。
特征选择问题:选择恰当的特征可以大幅提高分类的准确性,可以通过特征选择算法或者领域知识等方法选取合适的特征。
模型选择问题:不同的模型适用于不同的场景,在选择模型时需要考虑问题的复杂度、数据规模、特征维度等因素。
对于8分类问题,我们可以使用深度学习方法来解决,常用的模型包括卷积神经网络(CNN)、循环神经网络(RNN)等。
下面给出一个简单的代码示例,使用Keras框架搭建一个简单的CNN模型来解决8分类问题,并进行归一化处理:
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
# 读取CSV文件
data = pd.read_csv('data.csv')
# 分离X和y
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
# 归一化处理
scaler = MinMaxScaler()
X = scaler.fit_transform(X)
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 调整数据形状
X_train = X_train.reshape(X_train.shape[0], 10, 10, 1)
X_test = X_test.reshape(X_test.shape[0], 10, 10, 1)
# 搭建CNN模型
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(10, 10, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(8, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, batch_size=32, epochs=10, verbose=1, validation_data=(X_test, y_test))
# 评估模型
score = model.evaluate(X_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
需要注意的是,对于多分类问题,我们需要将标签进行one-hot编码(即将每个标签表示为一个向量,向量的长度等于类别数目,向量中只有对应的位置为1,其它位置为0)。示例代码中为简化,使用了Keras内置的categorical_crossentropy作为损失函数,对于不能使用该损失函数的情况,需要手动进行one-hot编码和损失函数的定义。
如果我的回答解决了您的问题,请采纳!