python爬虫运行没有结果的问题
python爬虫
http://vip.stock.finance.sina.com.cn/fund_center/index.html#hbphall
抓取所有基金的信息
我先写了基金代码的一部分,但是运行后没有结果,想要问问是什么问题
import requests
from bs4 import BeautifulSoup
import time
import random
import re
import pandas as pd
import matplotlib.pyplot as plt
class Jijin:
def __init__(self):
self.URL = "http://vip.stock.finance.sina.com.cn/fund_center/index.html#hbphall"
self.startnum = [i for i in range(0, 11652, 40)]
self.header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'}
def getinf(self):
self.num = []
# self.name = []
# self.unitvalue = []
# self.totalvalue = []
# self.performance1 = []
# self.performance2 = []
# self.performance3 = []
# self.performance4 = []
# self.performance5 = []
for start in self.startnum:
time.sleep(random.randint(1, 5)) # 伪装成人为随机时间点击
html = requests.get(self.URL, params={"start": str(start)}, headers=self.header)
soup = BeautifulSoup(html.text, "html.parser")
nums = soup.select(
'#divHBPH.p_r > div.relative_outer > div#cHBPH.fundTab.table.fblue > table > tbody > tr.red > td.colorize > a')
# names =
# unitvalues =
# totalvalues =
# performance1s =
# performance2s =
# performance3s =
# performance4s =
# performance5s =
for numi in nums:
self.num.append(numi.text)
print(self.num)
self.result = pd.DataFrame(zip(self.num))
# 没有返回结果
def print_result(self):
# print('*'*60)
pd.set_option('display.max_rows', None) # 显示pandas所有行
return self.result
# 返回一个结果
pass
if __name__ == '__main__':
cls = Jijin()
cls.getinf()
cls.print_result()
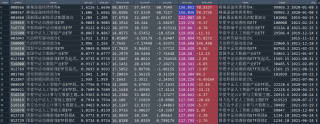
给你起个头,其它比较容易,一次请求了5000个,多了好像不行,试了9000个都可以,可以分两次
url="http://vip.stock.finance.sina.com.cn/fund_center/data/jsonp.php/IO.XSRV2.CallbackList['32sd$CbNssSUuKmO']/NetValueReturn_Service.NetValueReturnOpen?page=1&num=5000&sort=form_year&asc=0&ccode=&type2=0&type3="
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
dd=requests.get(url,headers).text
df=re.findall(r'{"total_num".*}',dd)[0]
data=pd.DataFrame(json.loads(df)['data'])
该回答内容部分引用GPT,GPT_Pro更好的解决问题
很可能是代码出现了问题,导致无法正确运行。例如在第9行的def _init(self)中,应该是def init(self);第22行的self.URL应该写成self.url; 第14行的self.header应该写成self.headers;以及其他可能出现问题的地方,要一一修改检查。
此外,还要考虑到抓取的目标网站是否有反爬虫机制、是否要添加cookie等等,如果有反爬虫机制,需要对自己的代码进行优化和改写,以便让代码更具通用性和可扩展性。
另外,如果想要实现多线程加快抓取速度,还需要考虑python的多线程实现方法,比如使用threading, multiprocessing, gevent或者其他的异步框架。
以上主要是代码问题,有时运行不出结果也可能是因为数据问题。比如基金信息不存在、数据格式不一致、数据量大导致无法正常输出,这些都是可能导致无法得到期望结果的原因。
总之,python仆虫运行不出结果的原因可能有很多:代码问题、数据问题、反爬虫机制以及多线程实现方法等。所以建议大家在运行python 仆虫时要仔仔细细地去检查代码和数据是否正常,并注意对代码进行优化,使之具有通用性和可扩展性。
如果回答有帮助,望采纳。
主要是tbody的问题,删了它。参考http://t.csdn.cn/X606v