python爬虫运行成功但是数据没有输出
我做一个爬取pubmed的爬虫来爬取文章标题和链接。
可是能正常运行但是怕去不了数据,我测试后他说未发现文章。可是我用之前的一个用过的爬虫爬取同样的网站,他能爬取出文章,这是为什么啊各位。
这个是运行但不出数据
import requests
from bs4 import BeautifulSoup
url = 'https://pubmed.ncbi.nlm.nih.gov/?term=cervical%20cancer%20treatment&filter=years.2020-2023'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50'
}
def get_articles(url):
# 发送HTTP请求,获取页面数据
response = requests.get(url, headers=headers)
html = response.text
# 解析HTML代码
soup = BeautifulSoup(html, 'html.parser')
# 找到包含文章信息的标签
article_tags = soup.select('.docsum-content')
# 提取每篇文章的标题和链接
results = []
for tag in article_tags:
title_tags = tag.select('.docsum-title > a')
if title_tags:
title = title_tags[0].get_text().strip()
link = 'https://pubmed.ncbi.nlm.nih.gov' + title_tags[0]['href']
results.append((title, link))
return results
if __name__ == '__main__':
for page in range(1, 6):
page_url = f'{url}&page={page}'
articles = get_articles(page_url)
for article in articles:
print(article[0])
print(article[1])
print('---')
if __name__ == '__main__':
for page in range(1, 6):
page_url = f'{url}&page={page}'
articles = get_articles(page_url)
print(f'Page {page}: {page_url} ({len(articles)} articles found)')
for article in articles:
print(article[0])
print(article[1])
print('---')
这是可以运行的代码
```python
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = "https://pubmed.ncbi.nlm.nih.gov/?term=cervical%20cancer%20treatment&filter=years.2020-2023"
num_pages = 10
data = []
for i in range(num_pages):
# Construct the URL for the current page
page_url = f"{url}&page={i+1}"
# Make a request to the page and parse the HTML using Beautiful Soup
response = requests.get(page_url)
soup = BeautifulSoup(response.content, 'html.parser')
# Find all the articles on the current page
articles = soup.find_all("div", class_="docsum-content")
# Extract the title and link for each article and append to the data list
for article in articles:
title = article.find("a", class_="docsum-title").text.strip()
link = article.find("a", class_="docsum-title")["href"]
data.append([title, link])
df = pd.DataFrame(data, columns=["Title", "Link"])
df.to_excel("cervical_cancer_treatment.xlsx", index=False)
```
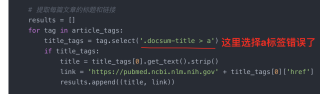
选择a标签的时候错误了,应该是 title_tags = tag.select('a'),这样选择每一个a标签,因为 article_tags = soup.select('.docsum-content') 已经定位到具体的div了,遍历的时候只需要遍历下边的a标签就可以了
import requests
from bs4 import BeautifulSoup
url = 'https://pubmed.ncbi.nlm.nih.gov/?term=cervical%20cancer%20treatment&filter=years.2020-2023'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50'
}
def get_articles(url):
# 发送HTTP请求,获取页面数据
response = requests.get(url, headers=headers)
html = response.text
# 解析HTML代码
soup = BeautifulSoup(html, 'html.parser')
# 找到包含文章信息的标签
article_tags = soup.select('.docsum-content')
# print('article_tags : ', article_tags)
# 提取每篇文章的标题和链接
results = []
for tag in article_tags:
title_tags = tag.select('a')
if title_tags:
title = title_tags[0].get_text().strip()
link = 'https://pubmed.ncbi.nlm.nih.gov' + title_tags[0]['href']
results.append((title, link))
return results
# if __name__ == '__main__':
# for page in range(1, 6):
# page_url = f'{url}&page={page}'
# articles = get_articles(page_url)
# for article in articles:
# print(article[0])
# print(article[1])
# print('---')
if __name__ == '__main__':
for page in range(1, 6):
page_url = f'{url}&page={page}'
articles = get_articles(page_url)
print(f'Page {page}: {page_url} ({len(articles)} articles found)')
for article in articles:
print(article[0])
print(article[1])
print('---')
该回答内容部分引用GPT,GPT_Pro更好的解决问题
这个问题可能是由于你编写的爬虫运行有误导致的,因为Beautifulsoup函数有一个参数是“parser”,用来声明html文档的解析器,这个参数可以指定使用html.parser,lxml或者html5lib来解析html文档,一般情况下,我们使用lxml来解析html文档,所以应该将Beautifulsoup函数的参数“parser”设置为“lxml”:
soup = Beautifulsoup(html, parser='lxml')
另外,在使用Beautifulsoup函数之前,也需要先对html文档进行一定的处理,也就是说需要将html文档转换成字符串,一般情况下可以使用requests.text属性来实现html文档的转换:
response = requests.get(url, headers=headers)
html = response.text
soup = Beautifulsoup(html, parser='lxml')
此外,在使用Beautifulsoup函数之前,还需要对html文档进行简单的格式化处理,也就是说需要将html文档中的标签正确的嵌套,例如在嵌套div标签时,开始标签必须和结束标签匹配,否则可能会导致Beautifulsoup函数无法正常工作。另外,在使用Beautifulsoup函数之前,也需要先引入requests和Beautifulsoup库:
import requests
from bs4 import Beautifulsoup
最后,还要注意在使用Beautifulsoup函数时,不要忘记添加一些其他的参数,例如features, encoding 和 parse_only 等参数。当然,最重要的是要定义一个正确的headers头来请求html文档:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36'
}
如果回答有帮助,望采纳。
该回答引用ChatGPT
如果有疑问可以恢复我
可能出现无法获取数据的原因有很多,这里给出几个可能导致问题的原因:
1、网站服务器的反爬虫机制,如IP封锁、请求头不合法等,这可能导致你的请求被服务器拒绝或被重定向到其他页面。
2、网络问题,如网络不稳定、请求过于频繁等,这可能导致请求失败或被服务器限制。
3、解析HTML代码的方式不正确,导致无法正确解析出所需的信息。
4、网站更新,导致HTML代码结构或元素选择器发生变化,导致你的爬虫无法正确解析。
6、网站数据量较少,导致你在爬取时未能找到任何数据。
为了确定问题的原因,你可以尝试一些调试技巧:
1、使用浏览器查看原始页面源代码,检查你的爬虫程序是否正确地提取了需要的元素。
2、使用requests库的response对象查看服务器返回的HTTP状态码,以确定请求是否成功。
3、调整请求头信息,尝试伪装成浏览器访问网站。
4、调整请求频率,防止请求过于频繁导致服务器限制。
5、使用代理IP,防止IP被服务器封锁。
在调试时,你可以先从一个较小的数据集开始,检查程序是否可以正确地提取所需的数据,逐步扩大数据集,最终确定问题的原因并解决它。
把这行代码
```python
title_tags = tag.select('.docsum-title > a')
改成下面这样就可以了
title_tags = tag.select('.docsum-title')
```
您的第一个代码没有返回任何结果而第二个代码却可以的可能原因有几个。
其中一个原因可能是第一个代码缺少第二个代码包含的关键信息,比如指定要爬取的页面数。
另一个可能原因是自从您上一次使用可工作的代码以来,网站发生了变化,这可能需要您相应地更新爬取代码。
此外,网站可能已经采取措施防止爬取,比如限制速率或封锁IP地址,这可能会阻止您的代码访问数据。
如果您怀疑问题在于网站的安全措施,您可以尝试使用一个可以帮助您绕过这些措施的爬取库,比如 scrapy 或 selenium。
此外,您可能还想检查网站的服务条款,以确保您的爬取活动不违反其政策。
参考GPT和自己的思路,根据你提供的代码,我没有看到任何明显的问题。可能是你的输出被重定向到其他地方或者输出没有被打印出来。你可以尝试在终端中运行该脚本来检查输出,或者将输出写入文件中,例如:
import requests
from bs4 import BeautifulSoup
url = 'https://pubmed.ncbi.nlm.nih.gov/?term=cervical%20cancer%20treatment&filter=years.2020-2023'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50'
}
def get_articles(url):
# 发送HTTP请求,获取页面数据
response = requests.get(url, headers=headers)
html = response.text
# 解析HTML代码
soup = BeautifulSoup(html, 'html.parser')
# 找到包含文章信息的标签
article_tags = soup.select('.docsum-content')
# 提取每篇文章的标题和链接
results = []
for tag in article_tags:
title_tags = tag.select('.docsum-title > a')
if title_tags:
title = title_tags[0].get_text().strip()
link = 'https://pubmed.ncbi.nlm.nih.gov' + title_tags[0]['href']
results.append((title, link))
return results
if __name__ == '__main__':
with open('output.txt', 'w', encoding='utf-8') as f:
for page in range(1, 6):
page_url = f'{url}&page={page}'
articles = get_articles(page_url)
f.write(f'Page {page}: {page_url} ({len(articles)} articles found)\n')
for article in articles:
f.write(article[0]+'\n')
f.write(article[1]+'\n')
f.write('---\n')
这段代码会将输出写入一个名为 output.txt 的文本文件中,你可以检查该文件来查看输出是否正确。
把这里改下就行
# 找到包含文章信息的标签
article_tags = soup.find_all("div", class_="docsum-content")
# 提取每篇文章的标题和链接
results = []
for tag in article_tags:
title_tags = tag.find_all('a', class_='docsum-title')
if title_tags:
title = title_tags[0].get_text().strip()
link = 'https://pubmed.ncbi.nlm.nih.gov' + title_tags[0]['href']
results.append((title, link))

吐槽下chatgpt的滥用,这几个回答根本解决不了问题,太书面了,估计都是对接的接口自动回答的,望采纳,谢谢
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7479373