在python中使用pandas读取Excel数据,重复数据被区分了
在python中使用pandas读取Excel数据,pandas将表格中重复数据作出了区分。
Excel中的数据如下所示

pandas读取的结果

如何做到重复数据不被区分
在pandas读取的函数read_excel()中增加header=None参数即可,同理也适用于read_csv()等函数,如果有用请采纳,谢谢。
import pandas as pd
file = "q.xlsx"
data = pd.read_excel(file,header=None) #reading file
print(data)
输出结果如下:
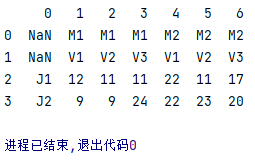
pandas读取excel默认是有列名的。列名不可能重复,所以做了区分。
按照你的要求,可以设置两层列名。详见下面的例子:

import pandas as pd
df = pd.read_excel(r"test.xlsx", header=[0, 1])
print('读取的列名有两层。第一层中有M1和M2两个列名,第二层中分别包含了V1和V2')
print(df)
M1V1 = df.loc[:, 'M1'].loc[:, 'V1']
print('读取时要逐次选定列名,比如要读取列名为M1下的V1列。先选定列名为M1,然后再选定列名为V1')
print(df.loc[:, 'M1'].loc[:, 'V1'])

你可以在EXCEL上把M1 V1两行合成一行,例如M1_V1、M1_V2之类
。这样读取时就不会出现这种问题。
该回答引用GPTᴼᴾᴱᴺᴬᴵ
在pandas中,读取Excel数据时可以使用pd.read_excel()方法。如果重复数据被区分了,可以考虑使用duplicated()方法来判断数据是否重复,然后使用drop_duplicates()方法删除重复数据。
以下是示例代码:
import pandas as pd
# 读取Excel文件
df = pd.read_excel('example.xlsx')
# 判断重复数据
is_duplicated = df.duplicated(['column_name'])
# 删除重复数据
df.drop_duplicates(['column_name'], inplace=True)
其中,column_name是需要判断的列名。
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7587130
- 这篇博客你也可以参考下:Python-Pandas库实现EXCEL数据拆分成不同的表