请求一个正则表达式, 关于中文注释的
<manifest xmlns="http://www.imsproject.org/xsd/imscp_rootv1p1p2" xmlns:imsmd="http://www.imsglobal.org/xsd/imsmd_rootv1p2p1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" >manifest>
// 语言配置
// 语言配置
language: {
enable: 1, // 是否启用国际化语言配置
/**
* 国际化默认语言
**/
<body>
要筛选出来的
helloword
sdfsdfsdfsdfsdfs要筛选出来的
<script>
请求帮忙一个正则表达式, 将 [要筛选出来的] 这6个汉字匹配出来.
其他在注释里的汉字或英文不匹配
<manifest xmlns="http://www.imsproject.org/xsd/imscp_rootv1p1p2" xmlns:imsmd="http://www.imsglobal.org/xsd/imsmd_rootv1p2p1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" ></manifest>
// 语言配置
// 语言配置
language: {
enable: 1, // 是否启用国际化语言配置
/**
* 国际化默认语言
**/
<body>
<!-- <div class="error-page">
<div class="err-box">f
<img src="static/img/stop.jpg" alt="">
<p id="message">课件播放器处理异常 </p>
</div>
</div> -->
要筛选出来的
helloword
<!-- sdf水电费水电费 -->
sdfsdfsdfsdfsdfs要筛选出来的
<script>
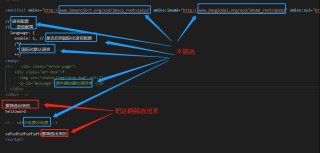
您好,按照我的理解,需求是使用正则匹配非注释中的中文字符,经过测试提出一种解决方案供参考:
1. 根据Unicode编码规则,匹配中文使用:[\u4e00-\u9fa5]
2. 排除单行注释,即忽略单行中出现//后的内容:/(?<!\/\/.*)[\u4e00-\u9fa5]+/g
3. 排除/**/包裹的多行注释:/(?<!\/\*(.(?<!\*\/)\n?)*)[\u4e00-\u9fa5]+/g
4. 同理,排除<!---->包裹的多行注释:/(?<!<!--(.(?<!-->)\n?)*)[\u4e00-\u9fa5]+/g
5. 整合为一个表达式:/(?<!(\/\*(.(?<!\*\/)\n?)*)|(<!--(.(?<!-->)\n?)*)|(\/\/.*))[\u4e00-\u9fa5]+/g
//Javascript代码测试
//匹配
console.log(content.match(/(?<!(\/\*(.(?<!\*\/)\n?)*)|(<!--(.(?<!-->)\n?)*)|(\/\/.*))[\u4e00-\u9fa5]+/g));
//替换
console.log(content.replace(/(?<!(\/\*(.(?<!\*\/)\n?)*)|(<!--(.(?<!-->)\n?)*)|(\/\/.*))[\u4e00-\u9fa5]+/g,''));
使用VS编辑器测试:
