transfomer预训练模型每次加载后结果不同
在hugging face上下载了一个预训练的模型,但是我发现每次加载后输出的结果都不一样
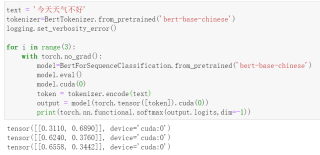
text = '今天天气不好'
tokenizer=BertTokenizer.from_pretrained('bert-base-chinese')
logging.set_verbosity_error()
for i in range(3):
with torch.no_grad():
model=BertForSequenceClassification.from_pretrained('bert-base-chinese')
model.eval()
model.cuda(0)
token = tokenizer.encode(text)
output = model(torch.tensor([token]).cuda(0))
print(torch.nn.functional.softmax(output.logits,dim=-1))
Huggingface 提供的预训练模型 bert-base-uncased 只包含 BertModel 的权重,不包括线性层 + 激活函数的权重。它的线性层 + 激活函数的权重是随机的,所以你的3次进去都是随机的,当然有差别。
该回答内容部分引用GPT,GPT_Pro更好的解决问题
每次加载预训练模型后输出的结果不一样,是因为在训练模型时模型参数的初始化都是随机的,也就是说每次初始化时参数的值是不一样的,这也就导致每次加载预训练模型后得到的结果也不一样。具体代码如下:
# 加载预训练模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
logging.set_verbosity_error()
for _ in range(3):
with torch.no_grad():
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
model.eval()
model.cuda(e)
token = tokenizer.encode(text)
output = model(torch.tensor([token]).cuda(e))
print(torch.nn.functional.softmax(output.logits,dim=-1))
因此,在使用预训练模型时,我们需要注意每次输出的结果可能都不一样,因此应该多次运行,以取得合适的结果。
如果回答有帮助,望采纳。