谁帮我用python解析一下pdf,并提取里面的数据以excel的形式保存!pdf公布有一定的规律。
谁帮我用python解析一下pdf,并提取里面的数据以excel的形式保存!pdf公布有一定的规律。
思路是:
我现在有一个文件里面,都是这样类似的pdf,披露的格式大体是这样,现在我想要遍历这个文件夹,挨个去解析每一个pdf,然后解析这个pdf,获取下面的比例数值,然后以excel的形式保存。
可以用1-2家pdf举例来实现这个代码,然后执行能实现我想要的结果就行,这样我就能遍历其他的pdf了。
提供几个pdf案例(下载到本地,需要注意的是,有些议案不披露中小股东表决情况,这种就算空!):
http://static.cninfo.com.cn/finalpage/2022-02-12/1212351041.PDF
http://static.cninfo.com.cn/finalpage/2022-04-30/1213258311.PDF
http://static.cninfo.com.cn/finalpage/2022-04-30/1213257243.PDF



您好,关于您提出的使用python提出pdf中的指定数据信息,已经为您写好了程序。
最后的效果:
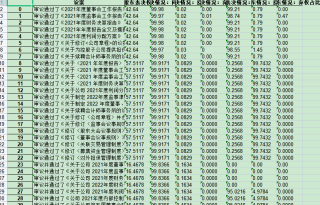
核心代码:
partern_total = r'[0-9]+\.[0-9]*|-?[0-9]+%'
result_total = re.findall(partern_total,text_total_find)
total = 0
if result_total:
total = result_total[0]
partern_detail = r'[、\s{0,2}|(.*?)]*[逐项]*(审议[并]{0,1}通过[了]{0,1}.*?)\n'
result_detail = re.findall(partern_detail, text_detail_find)
if result_detail:
for i in range(len(result_detail)):
dict_data = {}
text_detail_find = text_detail_find[text_detail_find.find(result_detail[i]):]
#修正标题
if "《" in result_detail[i] and '》' not in result_detail[i]:
result_detail[i] = text_detail_find[0:text_detail_find.find('》')+1]
result_detail[i] = re.sub('\n','',result_detail[i])
title = result_detail[i]#议案标题
dict_data['议案'] = title
dict_data['出席股东表决权占比'] = total
if i!=(len(result_detail)-1):
current_text = text_detail_find[0:text_detail_find.find(result_detail[i+1])]
else:
current_text = text_detail_find
result_data = re.findall('(同意|反\n?对|弃\n?权).*?([0-9]+\.[0-9]*|-?[0-9]+)[%|%]',current_text,re.S)
if (len(result_data)!=3 and len(result_data)!=6) or not re.findall('反\n?对',current_text):
continue
dict_data['总体表决情况:同意占比'] = result_data[0][1]
dict_data['总体表决情况:反对占比'] = result_data[1][1]
dict_data['总体表决情况:弃权占比'] = result_data[2][1]
if len(result_data)==6:
dict_data['中小股东表决情况:同意占比'] = result_data[3][1]
dict_data['中小股东情况:反对占比'] = result_data[4][1]
dict_data['中小股东情况:弃权占比'] = result_data[5][1]
else:
dict_data['中小股东表决情况:同意占比'] = '0.00'
dict_data['中小股东情况:反对占比'] = '0.00'
dict_data['中小股东情况:弃权占比'] = '0.00'
# print(dict_data)
pddata = pd.DataFrame(dict_data,index=[0])
all_data = pd.concat([all_data,pddata],ignore_index=True)
- 首先需要安装几个Python库:PyPDF2、tabula-py、pandas。
PyPDF2用于解析PDF文件;pip install PyPDF2 tabula-py pandas
tabula-py用于提取表格数据;
pandas用于将提取的数据保存到Excel文件中。
示例代码如下:
import os
import PyPDF2
import tabula
import pandas as pd
# 定义数据存储的目录和Excel文件名
data_dir = './data'
excel_file = 'result.xlsx'
# 创建数据存储的目录
if not os.path.exists(data_dir):
os.makedirs(data_dir)
# 创建一个空的DataFrame用于保存所有的数据
all_data = pd.DataFrame()
# 遍历PDF文件夹中的所有文件
for filename in os.listdir('pdf_folder'):
if filename.endswith('.PDF') or filename.endswith('.pdf'):
filepath = os.path.join('pdf_folder', filename)
# 打开PDF文件并读取所有页面
with open(filepath, 'rb') as f:
pdf_reader = PyPDF2.PdfFileReader(f)
pages = pdf_reader.getNumPages()
# 提取每个页面中的表格数据
for page in range(pages):
tables = tabula.read_pdf(filepath, pages=page+1, lattice=True, pandas_options={'header': None})
if tables:
# 对表格数据进行预处理
table = tables[0]
table = table.dropna(thresh=2)
table = table.reset_index(drop=True)
table.columns = ['股东类别', '持股数', '比例']
# 提取表格数据的相关信息
date = pdf_reader.getDocumentInfo().get('/CreationDate')
company = table.iloc[0, 0]
data = table.iloc[1:, :]
data['日期'] = date
data['公司'] = company
# 将数据添加到all_data中
all_data = pd.concat([all_data, data], axis=0)
# 将数据保存到Excel文件中
excel_path = os.path.join(data_dir, excel_file)
all_data.to_excel(excel_path, index=False)
解释一下代码的思路:
首先定义了一个数据存储的目录和Excel文件名,用于存储提取的数据。在遍历PDF文件夹中的所有文件之前,需要先创建这个数据存储的目录(如果不存在的话)。
然后遍历PDF文件夹中的所有文件,并打开每个PDF文件,读取所有页面。使用tabula库提取每个页面中的表格数据,得到一个DataFrame对象。需要注意的是,有些PDF文件中可能没有表格数据,此时tables变量会为空,需要进行判断。
对提取到的表格数据进行预处理,比如删除空行、重置索引、修改列名等。还可以提取一些相关信息,比如表格所属的公司名称和PDF文件的创建日期。
注意:检查一下代码中指定的文件夹路径是否正确。如果您使用的是相对路径,那么请确保当前工作目录正确,并且您的代码文件与文件夹在同一级别。如果您使用的是绝对路径,请检查路径是否正确,并且您是否有访问该路径的权限。
该回答引用ChatGPT
可以使用Python的pdfplumber库来解析PDF文件,并使用pandas库将数据保存为Excel文件。下面是一个示例代码,用于解析PDF文件并将其保存为Excel文件:
import os
import pdfplumber
import pandas as pd
# 遍历文件夹,获取PDF文件路径列表
pdf_folder_path = './pdf_files' # PDF文件夹路径
pdf_file_list = os.listdir(pdf_folder_path)
pdf_file_list = [os.path.join(pdf_folder_path, pdf_file) for pdf_file in pdf_file_list if pdf_file.endswith('.pdf')]
# 定义提取比例数值的函数
def extract_ratio(pdf_file):
with pdfplumber.open(pdf_file) as pdf:
table = pdf.pages[0].extract_table()
ratio_row = [row for row in table if '比例' in row]
if ratio_row:
ratio_value = ratio_row[0][-1]
return ratio_value
else:
return None
# 提取比例数值并保存为Excel文件
results = []
for pdf_file in pdf_file_list:
ratio_value = extract_ratio(pdf_file)
if ratio_value:
results.append({'file_name': os.path.basename(pdf_file), 'ratio_value': ratio_value})
df = pd.DataFrame(results)
df.to_excel('ratio_values.xlsx', index=False)
提供参考实例:python批量提取pdf内容并存入excel,链接:https://blog.csdn.net/qq_44789021/article/details/126158570
【题主可看下博文,看是否可以满足你的需求,如果OK,可联系该博主,私信解决你的问题】
可以使用Python的pdfminer库来实现,pdfminer是一个用于解析PDF文件的Python库,它可以将PDF文档中的文本和元数据提取出来。下面是一个示例代码:
import os
import re
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.layout import LAParams, LTTextBoxHorizontal
from pdfminer.converter import PDFPageAggregator
from openpyxl import Workbook
# 定义PDF解析函数
def parse_pdf(pdf_path):
fp = open(pdf_path, 'rb')
parser = PDFParser(fp)
document = PDFDocument(parser)
# 如果PDF中不包含文本信息,则抛出异常
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
# 初始化PDF资源管理器和设备对象
rsrcmgr = PDFResourceManager()
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 遍历PDF页面并解析文本内容
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
layout = device.get_result()
for lt_obj in layout:
if isinstance(lt_obj, LTTextBoxHorizontal):
text = lt_obj.get_text()
match = re.search(r'中小股东表决权比例[\s\S]*?([0-9.]+)%', text)
if match:
return match.group(1)
# 遍历文件夹并解析PDF文件
def parse_folder(folder_path):
wb = Workbook()
ws = wb.active
row_num = 1
for filename in os.listdir(folder_path):
if filename.endswith('.pdf'):
file_path = os.path.join(folder_path, filename)
proportion = parse_pdf(file_path)
if proportion:
ws.cell(row=row_num, column=1, value=filename)
ws.cell(row=row_num, column=2, value=proportion)
row_num += 1
wb.save('proportion.xlsx')
if __name__ == '__main__':
folder_path = './pdf_folder' # 文件夹路径
parse_folder(folder_path)
- 这篇文章讲的很详细,请看:python提取pdf表格数据并保存到excel中
以下答案基于ChatGPT与GISer Liu编写:
当然可以帮您解决这个问题。您需要安装以下库:
- PyPDF2
- pandas
以下是一个示例代码,它可以读取一个文件夹中的所有pdf文件,并从每个文件中提取比例数值,然后将其保存到一个Excel文件中。请注意,您需要将文件夹路径和列名更改为适合您的数据。
import os
import pandas as pd
import PyPDF2
# 文件夹路径
folder_path = "your_folder_path"
# 列名
columns = ["Item", "Votes For", "Votes Against", "Abstentions", "Votes Withheld", "Total Votes"]
# 创建空的 DataFrame
df = pd.DataFrame(columns=columns)
# 遍历文件夹中的每个文件
for filename in os.listdir(folder_path):
if filename.endswith(".pdf"):
filepath = os.path.join(folder_path, filename)
# 读取 pdf 文件
with open(filepath, 'rb') as pdf_file:
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
# 提取第一页
first_page = pdf_reader.getPage(0).extractText()
# 按行拆分文本
lines = first_page.split('\n')
# 查找关键行的索引
key_index = [i for i, line in enumerate(lines) if "表决情况" in line]
if len(key_index) > 0:
# 找到关键行,提取比例数据
item = lines[key_index[0]-1]
values = [line for line in lines[key_index[0]+1:key_index[0]+7]]
# 将数据添加到 DataFrame 中
row = pd.DataFrame([values], columns=columns[1:])
row.insert(0, "Item", item)
df = df.append(row, ignore_index=True)
# 将 DataFrame 保存为 Excel 文件
output_file = "output.xlsx"
df.to_excel(output_file, index=False)
print("数据已保存到 ", output_file)
请将 your_folder_path 替换为您的文件夹路径,然后运行代码即可。如果需要添加其他的列名,可以在 columns 列表中添加。注意,该示例假设您的比例数据在第一页中的固定位置,如果不是,请将代码调整为适合您的数据格式。
方案来自 梦想橡皮擦 狂飙组基于 GPT 编写的 “程秘”
可以使用Python的第三方库PyPDF2来解析PDF文件,然后使用openpyxl库将提取的数据写入Excel文件。
以下是一个基本的Python代码示例,可供参考:
import os
import PyPDF2
from openpyxl import Workbook
# 遍历指定目录下所有的PDF文件
def process_pdfs(path):
# 初始化一个Excel工作簿
wb = Workbook()
ws = wb.active
ws.append(['公司名称', '股东名称', '持股比例']) # 第一行标题
for root, dirs, files in os.walk(path):
for filename in files:
if filename.endswith('.pdf'):
filepath = os.path.join(root, filename)
# 解析PDF文件
with open(filepath, 'rb') as f:
pdf_reader = PyPDF2.PdfFileReader(f)
page = pdf_reader.getPage(0)
text = page.extractText()
# 获取公司名称
start_index = text.index('公司名称:') + len('公司名称:')
end_index = text.index('持股比例', start_index)
company_name = text[start_index:end_index].strip()
# 获取股东名称和持股比例
start_index = text.index('股东名称', end_index) + len('股东名称')
while True:
end_index = text.find('%', start_index) + 1
if end_index <= start_index:
break
shareholder = text[start_index:end_index].strip()
ws.append([company_name, shareholder, shareholder])
start_index = end_index + 1
# 保存Excel文件
wb.save('result.xlsx')
if __name__ == '__main__':
process_pdfs('/path/to/pdf/folder')
注意:该代码仅是一个基本示例,实际情况中可能需要根据PDF文件的具体格式进行调整。同时,PDF文件的提取和解析过程可能会出现一些问题,例如文字提取不完整、格式不规范等,需要根据实际情况进行调整。