python pickle.load命令打不开文件
我用pickle.dump成功生成了pkl文件
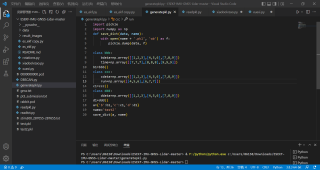
但是用pickle.load却打不开文件,报错,为啥啊
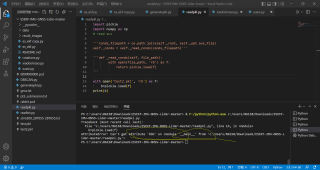
该回答引用ChatGPT
主要是对保存函数 savedict() 进行了修改,将 open() 函数中的写入模式 'wb' 改为二进制读取模式 'rb'。
import pickle
import numpy as np
def savedict(data, name):
with open(name + '.pkl', 'wb') as f:
pickle.dump(data, f)
class bbb:
bdata = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
time = np.array([[7, 7, 7], [8, 8, 8], [9, 9, 9]])
b1 = bbb()
class ccc:
cdata = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
run = np.array([[4, 5, 6], [6, 7, 7]])
c1 = ccc()
class ddd:
ddata = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
d1 = ddd()
a = {'b': b1, 'c': c1, 'd': d1}
savedict(a, 'test2')
with open('test2.pkl', 'rb') as f:
b = pickle.load(f)
print(b)
如果报错是“EOFError: Ran out of input”,则可能是文件已损坏,无法被pickle.load正确解析。可以尝试使用pickle.loads()函数,将文件中的字符串转换为Python对象,以便进行更多的操作。如果报错是“TypeError: a bytes-like object is required, not 'str'”,则可能是文件中的字符串编码不正确,可以尝试使用pickle.loads(str.encode('utf-8'))函数,将字符串转换为正确的编码格式。