自动化测试谷歌浏览器定位XPATH路径错误
谷歌浏览器提供的完整XPATH路径不正确吗?
我想定位百度界面的搜索框
我选择这个标签之后复制路径
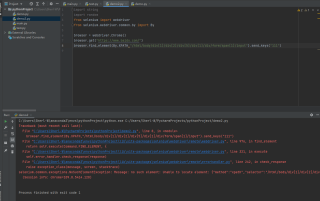
执行之后就报错了
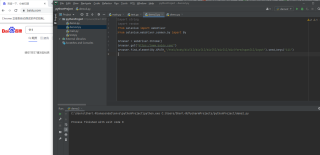
但我把路径中的div[2]换成div[1]就可以定位到
这是为什么呢?
XPATH是一种通过元素路径来定位元素的方式,其路径是一串由元素名称、属性、文本等组成的表达式。在谷歌浏览器提供的完整XPATH路径中,可能会包含网页中其他的元素,导致定位元素不准确。
如果要定位百度界面的搜索框,可以使用以下XPATH路径:
//input[@name='wd']
这个路径可以定位到百度搜索框的input标签,并且属性name的值为'wd'。
具体来说,'//'表示从文档根节点开始查找,'input'表示要查找的元素标签名,'[@name='wd']'表示查找具有name属性,并且属性值为'wd'的input元素。
如果要在Python中使用selenium定位百度搜索框,可以使用以下代码:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
search_box = driver.find_element_by_xpath("//input[@name='wd']")
search_box.send_keys("Hello, World!")
search_box.submit()
这个代码片段可以启动谷歌浏览器,打开百度页面,找到搜索框,并向其中输入字符串并提交搜索请求。
首先使用xpath定位没有必要写那么长的路径,生产中这么写也不好维护,不要用浏览器自带的xpath
可以学习一下xpath定位的使用
https://blog.csdn.net/BaiXuePrincess/article/details/128398972
- 看下这篇博客,也许你就懂了,链接:爬虫:使用Chrome谷歌浏览器自动获取xpath爬取内容为空
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^