python 里面 excel 有以下单元格的数据,如何实现以下代码
python 里面 excel 有以下单元格的数据,如何实现以下代码
在以下数据中:
找出
- 单元格含有2组(必须是2组)数字(可以是整数,也可以带小数点的数)
2.单元格含有: 付 /元/ 晒 / 下单 等 关键字, 符合其中一个关键词即可
找出符合 1.2 要求的单元格,提取出 对应单元格里面的2组数字 ,并对比大小
以及符合要求单元格的对应的行数
付5.9好平文字饭4元
付5.9好平文字饭4元
付6.9 好平反5元[胜利]
付6.9好平带图饭5元
付6.9好平饭4元
付7.9好平带图饭6元
付7.9好平文字饭6元
付7.9平给5[胜利]
付9.9好平带图饭7元
付9.9好平饭7元
付9.9好平饭7元
付款3.9元 晒图好平饭2.4圆
付款3元 晒图好平饭1.7圆
付款4.9 元 三图+15字,好平饭 3 圆
付款6.8元 晒图平价饭5圆
付款7.8元 晒图好平饭-5-圆
付款7.9元 三图十五字五星好平饭-5圆
付款7.9元 晒图好平返-5-圆
拍下7.8好瓶5元
下单4.39好瓶饭2
下单5.9hao平fan3.4
下单5.9收集瓶价给4
下单6.9好平饭5元
下单6.9晒图给5
下单6.9晒图给5
下单6.9晒图给5超值优惠
下单6.9晒图给5超值优惠
下单6.9晒图奖励4
下单6.9收集瓶价给5
下单6.9收集瓶价给5
下单6.9元 晒图平价饭-5-圆
下单7.3[红包]五?+hp晒图反5
下单7.7晒图好平反6[红包]
下单7.8hp晒图饭5
下单7.9,五?好平+晒图饭 5
下单7.9好瓶晒图饭5
下单7.9晒图给5超值优惠
下单7.9晒图给5圆
下单7.9晒图奖5超值优惠
下单7.9晒图奖5超值优惠
下单7.9五?好平晒图饭 5
限付6.9,晒图奖5
1.9?? 抢6包300系列抽纸[强]
2.9?? 抢6包420系列抽纸[强]
1.9?? 抢6包300系列抽纸[强]
3大包460系列仅1.9[红包]
1.9?? 抢6包300系列抽纸[强]
1.8??元 6包*300系列抽纸
1.9?? 抢6包300系列抽纸[强]
2.9?? 抢6包420系列抽纸[强]
1.9?? 抢6包300系列抽纸[强]
2.9[红包]6×420系列
1.7?? 6包420系列抽纸
1.9?? 抢3包460系列抽纸[强]
6包300系列到手仅1.9[红包]
1.9?? 抢6包300系列抽纸[强]
1.9??6包300系列抽纸
1.9?? 抢6包300系列抽纸[强]
2.9??元6包420系列原木抽纸
2.3??抢4包*460大包系列
你好,根据您的需求,代码如下,请采纳:
import pandas as pd
import re
df = pd.read_excel('A.xls',encoding='utf8')
for i in range(len(df)):
d = df.iloc[i]['data']
result = re.findall(r'\d+(?:\.\d+)?', d)
if len(result)==2 and re.findall(r'付|元|晒|下单', d):
if result[0] > result[1]:
print(f"行号:{i + 1},数字:{result[0]} > {result[1]}")
elif result[0] < result[1]:
print(f"行号:{i + 1},数字:{result[0]} < {result[1]}")
else:
print(f"行号:{i + 1},数字:{result[0]} = {result[1]}")
最后的结果大概如下:
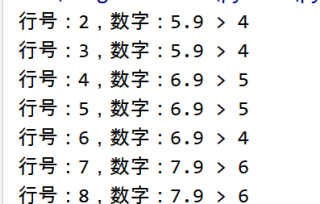
根据要求设计了表格,名称为data,表格内容为:

可以使用pandas和re正则表达式来实现
代码为:
import pandas as pd
import re
path1 = r'C:\Users\Desktop\data.xlsx' # 可替换为自己的路径
df1 = pd.read_excel(path1, dtype={'数据': str}) # 从excel读出数据
a = df1['数据'].tolist() # 将数据列转化为列表
pattern = r'[\u4ed8]|[\u5143]|[\u6652]|[\u4e0b\u5355]' # 设定匹配字符,分别对应付 /元/ 晒 / 下单
m = 1
for i in a:
m += 1
result1 = re.findall(r"\d+\.?\d*", i) # 匹配数字
result2 = re.findall(pattern, i) # 匹配文字
if len(result1) == 2 and len(result2) > 0:
if result1[0] > result1[1]:
print(f'满足要求的为 {i}, 在第 {m}行, {result1[0]}>{result1[1]}')
if result1[0] < result1[1]:
print(f'满足要求的为 {i}, 在第 {m}行, {result1[0]}<{result1[1]}')
运行结果为
满足要求的为 付5.9好平文字饭4元, 在第 2行, 5.9>4
满足要求的为 付5.9好平文字饭4元, 在第 3行, 5.9>4
满足要求的为 付6.9 好平反5元[胜利], 在第 4行, 6.9>5
满足要求的为 付6.9好平带图饭5元, 在第 5行, 6.9>5
满足要求的为 付6.9好平饭4元, 在第 6行, 6.9>4
满足要求的为 付7.9好平带图饭6元, 在第 7行, 7.9>6
满足要求的为 付7.9好平文字饭6元, 在第 8行, 7.9>6
满足要求的为 付7.9平给5[胜利], 在第 9行, 7.9>5
满足要求的为 付9.9好平带图饭7元, 在第 10行, 9.9>7
满足要求的为 付9.9好平饭7元, 在第 11行, 9.9>7
满足要求的为 付9.9好平饭7元, 在第 12行, 9.9>7
满足要求的为 付款3.9元 晒图好平饭2.4圆, 在第 13行, 3.9>2.4
满足要求的为 付款3元 晒图好平饭1.7圆, 在第 14行, 3>1.7
满足要求的为 付款6.8元 晒图平价饭5圆, 在第 16行, 6.8>5
满足要求的为 付款7.8元 晒图好平饭-5-圆, 在第 17行, 7.8>5
满足要求的为 付款7.9元 三图十五字五星好平饭-5圆, 在第 18行, 7.9>5
进程已结束,退出代码0
进程已结束,退出代码0
可见结果满足要求
如果问题得到解决请点 采纳~~
可以使用 Python 的 pandas 库来读取 Excel 文件并进行数据筛选和处理。下面是一份实现代码,其中包括了详细的注释。
python
import pandas as pd import re # 读取 Excel 文件,假设要处理的数据位于第一个 sheet 中 df = pd.read_excel('path/to/your/excel/file.xlsx', sheet_name=0) # 创建一个空的 DataFrame,用于存储符合要求的单元格数据 result = pd.DataFrame(columns=['Row', 'Value', 'Number1', 'Number2']) # 遍历每一行数据 for index, row in df.iterrows(): # 将当前行的单元格值转换为字符串 value = str(row.values[0]) # 使用正则表达式匹配包含 2 个数字和关键字的单元格数据,这里的字符你自己替换,CSDN发不出来 matches = re.findall(r'(\d+\.\d+)\D*(\d+\.\d+)\D*(付|元|晒|xiadan)', value) # 如果匹配到了数据,则将其添加到结果 DataFrame 中 if matches: for match in matches: # 提取匹配到的数字和关键字 number1 = float(match[0]) number2 = float(match[1]) keyword = match[2] # 将数据添加到结果 DataFrame 中 result = result.append({'Row': index+1, 'Value': value, 'Number1': number1, 'Number2': number2}, ignore_index=True) # 如果结果 DataFrame 不为空,则根据两个数字的大小排序并输出 if not result.empty: result = result.sort_values(['Number1', 'Number2'], ascending=[True, False]) print(result[['Row', 'Value', 'Number1', 'Number2']]) else: print('No matching cells found.')需要注意的是,上述代码中使用了正则表达式来匹配数据。具体来说,
\d+\.\d+匹配带小数点的数,\D*匹配任意非数字字符,括号用于分组。在re.findall方法中使用(\d+\.\d+)\D*(\d+\.\d+)\D*(付|元|晒|下单)匹配包含 2 个数字和关键字的单元格数据。由于可能存在多组匹配,因此在找到数据后需要使用一个嵌套循环将每一组数据都添加到结果 DataFrame 中。最后,根据两个数字的大小对结果 DataFrame 进行排序,并输出符合要求的单元格数据的行数、单元格值和两个数字。
- 你可以参考下这篇文章:2.Python读取excel数据
下面是一个可能的 Python 实现:
import re
def extract_numbers(text):
# 使用正则表达式提取文本中的数字
# 模式匹配2组数字,两组数字之间可以有任意数量的空格
pattern = r'(\d+(?:\.\d+)?)\s*(?:元|圆)?\s*(\d+(?:\.\d+)?)'
match = re.search(pattern, text)
if match:
# 将数字转换为浮点数并返回它们
return float(match.group(1)), float(match.group(2))
else:
return None
def find_matching_rows(data, keywords):
# 用于存储符合要求的行数的列表
matching_rows = []
# 遍历每行数据
for i, row in enumerate(data):
# 检查关键词是否存在于当前行中
if any(keyword in row for keyword in keywords):
# 提取数字并将其添加到匹配行列表中
numbers = extract_numbers(row)
if numbers:
matching_rows.append((i, numbers[0], numbers[1]))
# 返回匹配行的列表,按第一组数字升序排序
return sorted(matching_rows, key=lambda x: x[1])
# 测试
data = [
'付5.9好平文字饭4元',
'付5.9好平文字饭4元',
'付6.9 好平反5元[胜利]',
'付6.9好平带图饭5元',
'付6.9好平饭4元',
'付7.9好平带图饭6元',
'付7.9好平文字饭6元',
'付7.9平给5[胜利]',
'付9.9好平带图饭7元',
'付9.9好平饭7元',
'付9.9好平饭7元',
'付款3.9元 晒图好平饭2.4圆',
'付款3元 晒图好平饭1.7圆',
'付款4.9 元 三图+15字,好平饭 3 圆',
'付款6.8元 晒图平价饭5圆',
'付款7.8元 晒图好平饭-5-圆',
'付款7.9元 三图十五字五星好平饭-5圆',
'付款7.9元 晒图好平返-5-圆',
'拍下7.8好瓶5元',
'下单4.39好瓶饭2',
'下单5.9hao平fan3.4',
'下单5.9收集瓶价给4',
'下单6.9好平饭5元',
'下单6.9晒图给5',
'下单6.9晒图给5',
'下单6.9晒图给5超值优
import re
def extract_number(text):
pattern = r'\d+(\.\d+)?'
matches = re.findall(pattern, text)
if len(matches) == 2:
return tuple(float(match) for match in matches)
return None
def contains_keywords(text):
keywords = ['付', '元', '晒', '下单']
return any(keyword in text for keyword in keywords)
data = [
'付5.9好平文字饭4元',
'付5.9好平文字饭4元',
'付6.9 好平反5元[胜利]',
'付6.9好平带图饭5元',
'付6.9好平饭4元',
'付7.9好平带图饭6元',
'付7.9好平文字饭6元',
'付7.9平给5[胜利]',
'付9.9好平带图饭7元',
'付9.9好平饭7元',
'付9.9好平饭7元',
'付款3.9元 晒图好平饭2.4圆',
'付款3元 晒图好平饭1.7圆',
'付款4.9 元 三图+15字,好平饭 3 圆',
'付款6.8元 晒图平价饭5圆',
'付款7.8元 晒图好平饭-5-圆',
'付款7.9元 三图十五字五星好平饭-5圆',
'付款7.9元 晒图好平返-5-圆',
'拍下7.8好瓶5元',
'下单4.39好瓶饭2',
'下单5.9hao平fan3.4',
'下单5.9收集瓶价给4',
'下单6.9好平饭5元',
'下单6.9晒图给5',
'下单6.9晒图给5',
'下单6.9晒图给5超值优惠',
'下单6.9晒图给5超值优惠',
'下单6.9晒图奖励4',
'下单6.9收集瓶价给5',
'下单6.9收集瓶价给5',
'下单6.9元 晒图平价饭-5-圆',
'下单7.3[红包]五?+hp晒图反5',
'下单7.7晒图好平反6[红包]',
'下单7.8hp晒图饭5',
'下单7.9,五?好平+晒图饭 5',
'下单7.9好瓶晒图饭5',
'下单7.9晒图给5超值优惠',
'下单7
如果对您有帮助,请给与采纳,谢谢。
import pandas as pd
import re
# 读取 Excel 文件
df = pd.read_excel('your_file.xlsx', sheet_name='your_sheet_name')
# 定义正则表达式
regex = r'(\d+\.*\d*)\D*(\d+\.*\d*)'
# 遍历单元格,匹配符合要求的内容
result = []
for index, row in df.iterrows():
cell = str(row['your_column_name'])
if re.search(regex, cell) is not None and len(re.findall(regex, cell)) == 2:
matches = re.findall(regex, cell)
num1 = float(matches[0][0])
num2 = float(matches[1][0])
if num1 > num2:
result.append((index+1, num1, num2))
elif any(word in cell for word in ['付', '元', '晒', '下单']):
result.append((index+1, cell))
# 输出结果
for r in result:
print(r)
获得踏板的长宽厚几何参数的具体步骤如下:
1.提取点云法向量:法向量是指在每个点处的表面法线方向。它们可以使用法线估计方法(如法线最小二乘法)计算得出。在点云中,法向量可以用来表示曲率、方向等信息。常用的法向量估计方法包括Integral Image法和基于协方差矩阵的方法。
2.边界提取:在点云中找到点云的边界,用于后续的几何形状分析。可以使用3D点云形态学或区域增长算法进行边界提取。
3.PCA分析:PCA分析是一种基于线性代数的技术,它可以对点云数据进行降维处理。在点云数据中,PCA可以用来分析主要的形状特征,如长、宽、高等。具体来说,PCA将点云数据投影到主成分方向上,从而获得主要的形状特征。投影后的点云可以得到主成分分析的结果。在PCL库中,可以使用pcl::PCA类来实现PCA分析。
4.几何形状分析:几何形状分析是指在点云数据中分析形状特征。常见的几何形状分析方法包括:法线分析、曲率分析、表面积分、包围盒分析等。在PCL库中,可以使用pcl::NormalEstimation类来实现法线分析,使用pcl::PrincipalCurvaturesEstimation类来实现曲率分析,使用pcl::SurfaceIntegrals类来计算表面积分,使用pcl::getMinMax3D函数来计算包围盒。
总的来说,通过提取点云法向量和边界信息,可以获得点云的形状信息。通过PCA分析,可以将点云数据投影到主成分方向上,从而获得主要的形状特征。通过几何形状分析,可以分析点云的形状特征,如法线、曲率、表面积等。
可以使用 openpyxl 库来读取 Excel 文件,并使用正则表达式来匹配数字和关键字。以下是一个实现此任务的代码:
import re
from openpyxl import load_workbook
# 加载 Excel 文件
wb = load_workbook('data.xlsx')
ws = wb.active
# 定义正则表达式
num_pattern = r'\d+(\.\d+)?' # 匹配数字
keyword_pattern = r'(付|元|晒|下单)' # 匹配关键字
# 遍历所有单元格
for row in ws.iter_rows():
for cell in row:
# 在单元格中查找数字和关键字
nums = re.findall(num_pattern, cell.value)
keywords = re.findall(keyword_pattern, cell.value)
# 如果找到了 2 组数字和符合要求的关键字
if len(nums) == 2 and any(kw in keywords for kw in ['付', '元', '晒', '下单']):
# 提取数字并比较大小
num1, num2 = float(nums[0]), float(nums[1])
if num1 > num2:
print(f"Cell '{cell.coordinate}' has {num1} and {num2} with keywords {keywords}")
该代码会遍历 Excel 文件中的所有单元格,对于每个单元格,使用正则表达式匹配其中的数字和关键字,然后判断是否满足题目要求。如果满足要求,则提取数字并比较大小,同时打印该单元格的坐标、数字和关键字。