hive创建带复杂类型数据列的表时报错,如何解决?
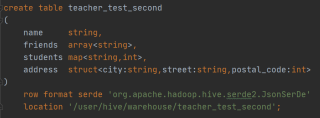
使用row format指定SERDE会出现报错

虽然能成功创建表出来,但是这样创建出来的表不能使用alter table……语句新增或修改列,会出现报错
[2023-02-15 16:56:29] [08S01][1] Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Error: type expected at the position 0 of '::::map<string,int>' but '<' is found.

因为你建的teacher_test没有指定复杂数据类型
根据你的报错内容,我猜测你的问题可能是由于你使用了不支持复杂类型数据的存储格式导致的。hive支持的复杂类型数据有array、map、struct和uniontype,但是并不是所有的存储格式都支持这些类型。例如,textfile、sequencefile和rcfile都不支持复杂类型数据,而parquet、orc和avro都支持复杂类型数据。
为了解决这个问题,你可以在创建表时,指定一个支持复杂类型数据的存储格式,例如parquet。下面是一个示例代码:
CREATE TABLE teacher (
id INT,
name STRING,
courses ARRAY<STRING>,
salary MAP<STRING, DOUBLE>,
info STRUCT<age: INT, gender: STRING, address: STRING>
) STORED AS PARQUET;
你Hive版本是多少啊,支持json格式吗。好像要3.xx版本的才能支持Json格式的
你可以参考一些官网 https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-JSON

hive-site 里加一行 metastore.storage.schema.reader.impl=org.apache.hadoop.hive.metastore.SerDeStorageSchemaReader 然后重启hive服务,重新执行以下这些操作 试一下,序列化的问题
该回答引用ChatGPT
如果您在创建 Hive 表时遇到了复杂类型数据列的问题,可能有几种原因。下面是一些可能导致此问题的原因和对应的解决方案:
1、复杂类型错误:请检查您在创建表时是否正确定义了复杂类型数据列。Hive 支持多种复杂类型数据列,例如 ARRAY、MAP、STRUCT 等。您可以使用类似于以下代码的语法来定义表中的复杂类型数据列:
CREATE TABLE mytable (
myarray ARRAY<STRING>,
mymap MAP<STRING, INT>,
mystruct STRUCT<field1:STRING, field2:INT>
);
请注意,您需要在尖括号(< 和 >)中指定复杂类型的数据类型。
2、分隔符问题:在定义表中的复杂类型数据列时,请确保您正确指定了数据的分隔符。对于 ARRAY 类型,数据应该使用逗号分隔。对于 MAP 类型,数据应该使用冒号分隔键值对,并使用逗号分隔不同的键值对。例如:
CREATE TABLE mytable (
myarray ARRAY<STRING>,
mymap MAP<STRING, INT>,
mystruct STRUCT<field1:STRING, field2:INT>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':';
在上面的示例中,我们使用 ROW FORMAT DELIMITED 指定了行的格式,并使用 FIELDS TERMINATED BY ',' 指定了数组元素之间的分隔符。我们还使用 COLLECTION ITEMS TERMINATED BY ',' 指定了 MAP 中键值对之间的分隔符,并使用 MAP KEYS TERMINATED BY ':' 指定了键和值之间的分隔符。
3、数据类型不匹配:请确保您在定义表中的复杂类型数据列时使用了正确的数据类型。例如,如果您尝试将一个字符串插入到 ARRAY 类型的列中,就会导致数据类型不匹配的错误。
4、其他问题:如果上述方法无法解决问题,请确保您使用的是正确的 Hive 版本,并查看 Hive 日志以获取更多信息。您还可以尝试重新启动 Hive 服务或使用其他方法来创建表。如果您的数据集非常大,则可能需要优化 Hive 查询以提高查询性能。
在 Hive 中创建带有复杂类型的列时,需要确保数据类型和格式的正确性,否则可能会遇到错误。具体来说,可以根据以下步骤尝试解决问题:
1.确保使用正确的数据类型
在创建表时,确保使用正确的数据类型来定义带有复杂类型的列。例如,如果要创建一个包含数组的列,则可以使用 ARRAY 数据类型。如果要创建一个包含映射的列,则可以使用 MAP 数据类型。如果要创建一个包含结构的列,则可以使用 STRUCT 数据类型。如果定义的数据类型不正确,则可能会导致错误。
2.确保使用正确的数据格式
在创建表时,还要确保使用正确的数据格式来定义带有复杂类型的列。例如,对于 ARRAY 数据类型的列,可以使用以下格式来定义数组的元素类型:
array<element_type>
对于 MAP 数据类型的列,可以使用以下格式来定义映射的键和值的类型:
map<key_type, value_type>
对于 STRUCT 数据类型的列,可以使用以下格式来定义结构的字段名称和类型:
struct<field1:data_type1, field2:data_type2, ...>
3.检查数据格式是否正确
如果数据格式不正确,则可能会导致创建表时出现错误。因此,确保在创建表时使用正确的数据格式。例如,如果要创建一个包含数组的列,但使用了错误的格式,则可能会导致错误。
4.检查是否有无效的字符或语法错误
在创建表时,还要检查是否有无效的字符或语法错误。例如,如果在定义列时包含了无效的字符或使用了错误的语法,则可能会导致错误。可以使用 Hive 的语法检查功能来检查是否存在这些错误。
综上所述,要解决在 Hive 中创建带有复杂类型的列时遇到的错误,需要确保使用正确的数据类型和格式,并检查是否有无效的字符或语法错误。
根据您提供的截图,报错信息显示Hive表操作时遇到了HDFS的异常,具体来说是因为HDFS中的/tmp/hive目录权限不足,导致无法创建表或在表中添加新列。
一、解决方法:
1.首先,检查HDFS目录的权限是否正确。确保HDFS中的/tmp/hive目录对于Hive用户(一般是hive)具有读写权限。
2.如果/tmp/hive目录权限正确,可以尝试在Hive CLI中执行以下命令进行修复:
$ hive --service metastore
hive> ALTER TABLE teacher_test ADD COLUMNS (age INT);
其中,Hive --service metastore 命令将在Hive Metastore服务中打开Hive CLI,并且 ALTER TABLE 命令将为表teacher_test添加一个age列。
3.如果以上方法都没有解决问题,可以尝试清空Hive Metastore的元数据,并重新创建表。在清空Hive Metastore元数据之前,最好备份元数据以便以后恢复。可以使用以下命令清空:
$ schematool -initSchema -dbType derby
这将使用Derby数据库重新初始化Hive Metastore的元数据。
希望这些解决方法可以帮助您解决问题。