如何对dataframe进行计算筛选?
问题遇到的现象和发生背景
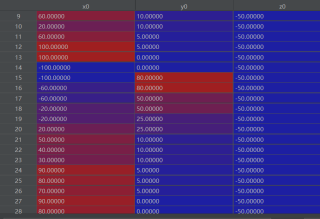
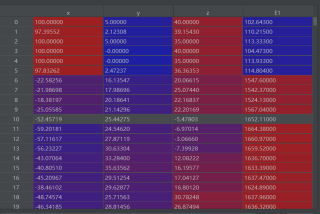
这两个表是csv格式的,我利用pd加载为dataframe了。
问题:对表1中的每一个(x0,,y0,z0)筛选出在表2中一定范围内的点,然后进行接下去计算
例如:如果表2中的(x,y,z)满足(x 0- x) ^ 2 + (y0 - y) ^ 2 + (z0 - z) ^ 2 <= 1000则认为是符合的。
我的解答思路和尝试过的方法,不写自己思路的,回答率下降 60%
原本想转化为矩阵然后进行计算,但是发现不太行。
想利用for循环对表1进行循环,但是有点写不下去
您可以使用Pandas的运算符实现上述逻辑。
首先,计算两个表格中点之间的欧几里得距离:
import numpy as np
table1['dist'] = np.sqrt((table1['x0'] - table2['x'])**2 + (table1['y0'] - table2['y'])**2 + (table1['z0'] - table2['z'])**2)
然后,对于每一个(x0,y0,z0)筛选距离小于等于1000的点:
result = table2[table1['dist'] <= 1000]
最后,对于每一个(x0,y0,z0),您可以使用相同的代码计算结果:
for i in range(table1.shape[0]):
x0, y0, z0 = table1.iloc[i, 0], table1.iloc[i, 1], table1.iloc[i, 2]
result = table2[(table2['x'] - x0)**2 + (table2['y'] - y0)**2 + (table2['z'] - z0)**2 <= 1000]
# Do something with the result
希望这对您有所帮助。
如果你是在使用Python Pandas库,可以使用以下方法对数据框进行计算和筛选:
1.筛选行:可以使用布尔索引或布尔掩码来筛选数据框中满足特定条件的行。例如:
df = df[df['column_name'] > value]
2.计算:可以使用基本数学运算符(+,-,*,/)来对数据框进行计算,也可以使用pandas内置函数(例如mean,sum,max)进行计算。例如:
df['new_column'] = df['column_1'] + df['column_2']
3.分组:可以使用groupby函数对数据框进行分组,并进行聚合操作(例如mean,sum,count)。例如:
grouped = df.groupby('column_name')
result = grouped.agg({'column_1': 'mean', 'column_2': 'sum'})
这些只是pandas的一些基本功能,更多的细节可以参考pandas官方文档。
1、基于条件的筛选:您可以使用布尔索引来选择 DataFrame 中符合特定条件的行。例如,您可以选择 "Age" 列中大于 30 的所有行:
df[df["Age"] > 30]
2、计算指标:您可以使用 DataFrame 的 apply() 方法或其他函数(如 mean()、median()、sum() 等)来计算 DataFrame 中的指标。例如,您可以计算 "Age" 列的平均值:
df["Age"].mean()
3、分组计算:您可以使用 groupby() 方法将 DataFrame 按特定列分组,然后计算分组后的指标。例如,您可以按 "Gender" 列将 DataFrame 分组,并计算每组 "Age" 列的平均值:
df.groupby("Gender")["Age"].mean()
这仅是几种常用的计算筛选方法,您还可以使用其他函数,如 merge()、pivot_table()、sort_values() 等,来进一步处理和分析您的数据。
- 文章:(六)DataFrame的操作 中也许有你想要的答案,请看下吧