Python如何用pandas读取excel并绘图
问题遇到的现象和发生背景
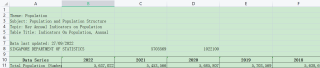
遇到的现象和发生背景,请写出第一个错误信息 数据在excel的T5表的A10:BV11,后面几行代码表示我想要让X存储data,Y存储year并绘制以X为横坐标对应Y纵坐标的图(但是无法实现,不知道该怎么写)
用代码块功能插入代码,请勿粘贴截图。 不用代码块回答率下降 50%
import numpy as np
import sklearn.linear_model as lm
import matplotlib.pyplot as plt
import pandas as pd
df=pd.read_excel('data.xlsx',sheet_name='T5',header=9,nrows=1)
data=df.iloc[0]
X=data
le=LabelEncoder()
Y=le.fit_transform(...)
Y=pd.Series(Y)
plt.plot(X,Y)
运行结果及详细报错内容
我的解答思路和尝试过的方法,不写自己思路的,回答率下降 60%
我想要达到的结果,如果你需要快速回答,请尝试 “付费悬赏”
data=df.iloc[0]
X=data[1:]
le=LabelEncoder()
Y=le.fit_transform(df.columns[1:])
Y=pd.Series(Y)
plt.plot(X,Y)
您好,如果有用请点击右侧采纳
首先,如何把表格转为Dataframe完成了(实在不行另起一个工作簿(sheet),用pd.read_excel()/pd.read_csv()指定工作簿完成)
那么问题就在于如何获取对应的X和Y
让X存储data,Y存储year
两种实现思路:
第一种,重新设定X为后续的列名(columns),然后Y取对应的值,适用于只有一条数据。

第二种,多条数据时,遍历Dataframe的index,对每一行进行绘图(同样以年份做X,Y为对应的值),plt有subplot可以拼接起每一行对应的图像。最终结果就是多条线。

。。。
其实我最常用的还是power bi哈哈哈哈没这么多事情
- 关于该问题,我找了一篇非常好的博客,你可以看看是否有帮助,链接:pandas读取 Excel 文件超长报错