python 爬虫并保存到excel文件
问题遇到的现象和发生背景
Python 爬虫
如何将网站 https://www.bse.cn/nq/nqzqlistlgb.html 中地方政府债下显示的内容 和网站 https://www.bse.cn/nq/nqzqlistgb.html 中国债下显示的内容爬虫并保存到excel中?
遇到的现象和发生背景,请写出第一个错误信息
尝试用以下代码,但是生成的excel中只有第一行标题,没有内容
用代码块功能插入代码,请勿粘贴截图。 不用代码块回答率下降 50%
import re
import time
import datetime
import openpyxl
import parsel as parsel
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
url = 'https://www.bse.cn/nq/nqzqlistgb.html'
driver = webdriver.Chrome(executable_path='chromedriver.exe')
driver.get(url=url)
el_search = driver.find_element(by=By.XPATH, value='//*[@id="root"]/div[4]/div/div/div[1]/div[1]/div/div[1]')
# 点击
el_search.click()
time.sleep(3)
html_data = driver.page_source
#print(html_data)
selector = parsel.Selector(html_data)
results = selector.css('#root > div.mw-page > div > div > div.col-sm-12.col-md-9.col-md-push-3 > div.mw-box-content > div').getall()
#print(results)
#print(type(results))
#print(len(results))
len_results = len(results)
if len_results == 1 and results[0] == '':
print("no result")
else:
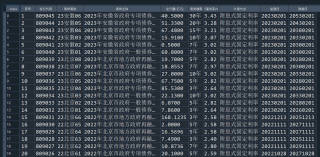
fieldnames = ['序号', '发行代码', '债券简称', '债券全称', '发行量(亿元)', '债券期限', '票面利率(%)', '计息方式', '起息日', '到期日']
work_book = openpyxl.Workbook()
work_book.create_sheet()
work_sheet = work_book.active
work_sheet.append(fieldnames)
for page in range(1, 5):
selector1 = parsel.Selector(driver.page_source)
results1 = selector1.css('#root > div.mw-page > div > div > div.col-sm-12.col-md-9.col-md-push-3 > div.mw-box-content > div').getall()
for r in results1[1:-1]:
row = re.findall(
'(.*?)(.*?)(.*?)(.*?)(.*?)(.*?)('
'.*?)(.*?)(.*?)(.*?)(.*?)',
r)[0]
print(list(row))
print(type(row))
work_sheet.append(list(row))
time.sleep(3)
if page < 5:
driver.find_element(by=By.LINK_TEXT, value='next').click()
time.sleep(5)
n = datetime.datetime.now().strftime('%m%d')
work_book.save(n + '_' + 'BJS_Code_Check' + '.xlsx')
print('file written successfully')
运行结果及详细报错内容
我的解答思路和尝试过的方法,不写自己思路的,回答率下降 60%
我想要达到的结果,如果你需要快速回答,请尝试 “付费悬赏”
我用的edge,你改成chrome应该一样的
import time
from lxml import etree
from selenium import webdriver
import pandas as pd
from selenium.webdriver.common.by import By
#保存每页数据函数
def get_page_data(all_data):
data=[]
for n,i in enumerate(dd):
data.append(str(i))
if (n+1)%10==0:
all_data.append(data)
data=[]
url = 'https://www.bse.cn/nq/nqzqlistlgb.html'#地方债卷
url2='https://www.bse.cn/nq/nqzqlistgb.html'#国债
driver = webdriver.Edge()
driver.get(url)#修改url就行
driver.maximize_window()
driver.implicitly_wait(10)
time.sleep(3)
html=etree.HTML(driver.page_source)
dd=html.xpath('//*[@id="table"]/table/tbody//text()')
#获取多少页
pages=html.xpath('//*[@href="javascript:;"]//text()')
page=0
for i in pages:
if str(i).isnumeric():
page+=1
all_data=[]
get_page_data(all_data)
#获取剩下每页数据
for i in range(page):
next_click=driver.find_element(By.LINK_TEXT,f'{i+2}')
next_click.click()
time.sleep(1)
html=etree.HTML(driver.page_source)
dd=html.xpath('//*[@id="table"]/table/tbody//text()')
get_page_data(all_data)
time.sleep(2)
#处理数据保存
data=pd.DataFrame(all_data)
data.columns=['序号', '发行代码', '债券简称', '债券全称', '发行量(亿元)', '债券期限', '票面利率(%)', '计息方式', '起息日', '到期日']
# data.to_excel('e:/地方债.xlsx',index=False)
不会python,其它语言的爬虫要不要,可以分享源码
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7739093
- 你也可以参考下这篇文章:python保存excel文件列宽自适应解决方案