Pandas合并前缀类似的行
问题遇到的现象和发生背景
在进行网页路径分析时想要将一些第一列字符串类似(比如abcde与abcdf,abcd这个前缀相同)的行求和
用代码块功能插入代码,请勿粘贴截图。 不用代码块回答率下降 50%
import pandas as pd
import numpy as np
df = pd.read_csv(r'C:\Users\Leo90\Downloads\data-export.csv',encoding='utf-8', header=None, sep='\n')
df = df[0].str.split(',', expand=True)
df=df.iloc[:,[0,1,2,3,4,5,6,7]]
df=df.replace(to_replace='None',value=np.nan).dropna()
df=df.reset_index(drop=True)
columnNames = df.iloc[0]
df = df[1:]
df.columns = columnNames
df.groupby('网页路径和屏幕类').head()
运行结果及详细报错内容
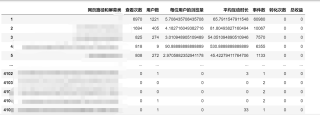
我的解答思路和尝试过的方法,不写自己思路的,回答率下降 60%
想要使用str.contain来合并相似列,但这样只能一种前缀合并一次且不知道该怎么求和(用SUM是不是可以呀)
我想要达到的结果,如果你需要快速回答,请尝试 “付费悬赏”
有许多个类似前缀的列我想要将他们分组行求和,将这几千行数据转化为几十行合并后的数据
新年好,这边梳理一下解决思路。望采纳
1、数据 ---- 我们现在有几千条处理后的数据
2、目标 : 根据第一列"最长前缀" 来进行合并,比如‘abcde’与‘abcdf’,abcd这个前缀相同。
解决思路 :
① : 数据载入及处理(楼主已完成)
② : 将每一行第一列转为List1(简单)
③ : 对List1中各项进行最长前缀/最大相似值进行 计算 (疯狂),计算后的结果与原数据组合成List2[['列名','公共前缀'],...] (简单)
④ : 根据List2对应关系,原Dataframe增加对应列('公共前缀') (简单)
⑤ : 根据‘公共前缀列’ 进行 df.groupby() .agg(...) (简单 )
所以难在第几步,难在第三步!
要解决第三步,要规定好匹配/分类的规则,是'最长前缀'(即a、b两项都从首位开始匹配)
还是 '最长公共值' (a,b两项任意匹配,如'kabcde' 和 ‘bcda’ 也能匹配出bcd)
然后要解决的是如何分群(即我不能拿4000条数据去求最长前缀/公共值,我得分成几种/几十种来找各自的结果)
这里首先给出最长前缀的代码
class Solution(object):
def longestCommonPrefix(self, strs):
"""
:type strs: List[str]
:rtype: str
"""
res=""
min_len=0
if strs=="":
return res
####遍历每个字符串求最小字符串长度
for str in strs:
if min_len==0:
min_len=len(str)
elif min_len>len(str):
min_len=len(str)
for str in strs:
for str1 in strs :
if str!=str1 :
if str[0]==str1[0] :
pass
else :
return ''
for i in range(0,min_len):
for str in strs:
for str1 in strs :
if str!=str1:
if str[:i]==str1[:i]:
pass
else :
return res
res=strs[0][0:i]
return res
分群的方法 :
首先,无论如何分群,必定存在部分数据孤孤单单(一网址一类)
数据量少的情况,可以按最终计算指标(查看次数/网页流量)倒序排列后对比前20?50 ? 浏览量大于1000? 的网址
预设每个群体的结果,然后开始分群(代表性~) ,看最终适配数量(例如4000用户最终3500户在预设群体内)
数据量爆炸的情况 : 需要更精细的分群方法,使结果趋向于最优/满足目标即可
估计运算量极大,推荐预设分群结果值减少一定运算量。
-------------------------敷衍的分割线-----------------------------
我是很想上手操作一下的,这不是懒得自己造数据了嘛。
如果有更好的解决办法,欢迎私信踢我。
- 这篇文章讲的很详细,请看:使用 pandas 遇到的报错
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^