python,爬虫,为什么会出现乱码
跟着写的代码,但是运行出来是乱码,生成的html运行出来也是乱的
图:、
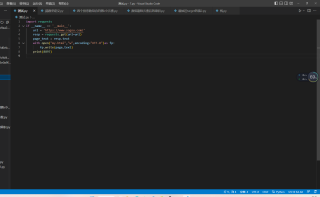
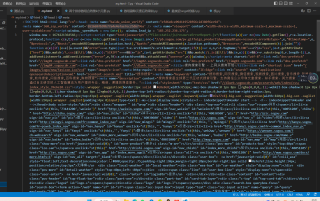
尝试了很多次都是错的
如果要解决乱码问题,可以修改requests.get().text语句,如下所示:
import requests
resp = requests.get("https://www.baidu.com").content
这会以字节的形式返回数据,不会在数据传递过程中因为模块的自动编译,产生编译错误。
最后,将resp按照字节的写入方式写入文档,创建html。
注意:这一系列方法生成的html文件无法获得百度网页的js图形渲染(尤其是动态)效果。
with open('test_html.html','ab+') as f:
f.write(resp)
f.close()
附图:
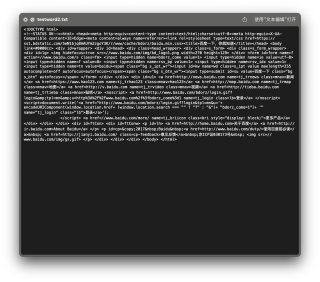
(图中的动态Baidu logo就没有获取到)
1、代码没有问题
2、网页做了扰乱,所以返回的东西看起来密密麻麻的
3、有没有可能,你使用的这些东西html,没有图片呢(js动态加载出页面内容,所以你没爬到全部内容),所以你运行出来只有一个小框架