python处理超大(12.3GB)CSV文件,获取指定关键词所在行的数据输出为新CSV文件
筛选一个12.3GB的EXCEL文件中的关键词所在行的数据,太大了打不开。关键词由一个小文件决定,小文件(20.6MB)显示如下:
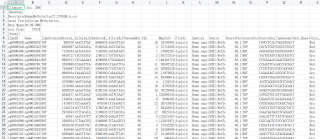
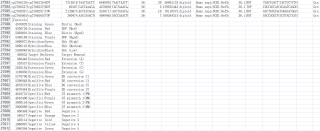
前七行无用,第八行是表头,从第九行开始往后就是数据,其第一列的cg00000292、cg00002426...就是关键词。
已知大文件数据的第一列也是cg+编号,大文件和小文件该列数据是有重合cg编号的。根据小文件中存在的cg序号所在行,提取大文件中的有对应cg序号所在行的数据,输出新的文件。
我是通过csv显示的大文件:
import csv
with open('大文件.csv', 'r') as f:
reader = csv.reader(f)
print(type(reader))
for row in reader:
print(row)
显示结果为:
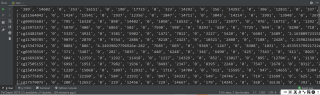
但我看不到像小文件截图中显示的,类似小文件的前七行和后几行这样的信息。可以确定cg所在行的数据的开头也是是cg+编号,所以可以因此筛选。
举个例子说明一下问题:假设大文件是这样的话:

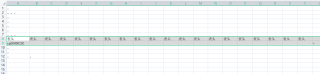
而只有cg00000292也出现在小文件的第一列cg编号中,所以筛选大文件输出的新文件为:
我一开始的思路:①用一段代码先:获得大文件中每个cg编号的所在行数②去和小文件对应,获得重复cg编号有哪些,根据其在大文件中对应的行数,输出大文件这些行获得新excel文件实现筛选。
但是文件实在太大了,处理不周到昂。
你可以先测试一下,用pandas,如果数据太大,你还可以先切一部分数据出来看看
import pandas as pd
dd=pd.read_csv('大文件.csv')
#数据切片
df=dd[0:100]
print(df)
data=dd[dd.iloc[:,0]=='cg00000292']
#如果知道第一列表头
data=dd[dd['列名']=='cg00000292']
- 给你找了一篇非常好的博客,你可以看看是否有帮助,链接:【python的读取csv文件数据】 已解决
- 同时,你还可以查看手册:python-csv --- CSV 文件读写 中的内容
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632