想通过python对制定文件夹内所有文本文件的内容进行按文件名和日期区别的归集
想通过python对制定文件夹内所有文本文件的内容进行按文件名和日期区别的归集,日期一列,内容股票名称一列,代码一列,来自的文件名一列,来自文件日期生成一列,(所有文件的内容都是固定的“股票名称(股票代码)”格式),归集写入Excel。然后每天接着之前的内容写入。
可以使用 Python 的 os 模块来遍历文件夹中的文本文件,然后使用正则表达式提取文件中的股票名称和股票代码。
为了将数据写入 Excel,可以使用 pandas 库的 DataFrame 类和 ExcelWriter 类。首先,你需要创建一个空的 DataFrame,然后逐个遍历文件并将每个文件中提取的信息添加到 DataFrame 中。最后,使用 ExcelWriter 将 DataFrame 写入 Excel。
import os
import re
import pandas as pd
# 遍历文件夹中的文件
folder_path = "path/to/folder"
file_list = []
for file_name in os.listdir(folder_path):
if file_name.endswith(".txt"):
file_list.append(file_name)
# 创建 DataFrame
columns = ['date','name','code','file_name','file_date']
df = pd.DataFrame(columns=columns)
# 遍历文件并提取信息
for file_name in file_list:
file_path = os.path.join(folder_path, file_name)
with open(file_path, "r") as file:
file_content = file.read()
match = re.search(r"(.*)\((.*)\)", file_content)
if match:
name, code = match.groups()
date = pd.datetime.now()
file_date = os.path.getmtime(file_path)
df = df.append({'date':date,'name':name,'code':code,'file_name':file_name,'file_date':file_date},ignore_index=True)
# 将 DataFrame 写入 Excel
with pd.ExcelWriter("output.xlsx") as writer:
df.to_excel(writer, sheet_name='Sheet1')
import os
import re
import pandas as pd
def collect_data_from_files(folder_path):
stock_data = []
for file_name in os.listdir(folder_path):
if not file_name.endswith('.txt'):
continue
file_path = os.path.join(folder_path, file_name)
with open(file_path, 'r') as f:
file_content = f.read()
match = re.search(r'(.*)\((.*)\)', file_content)
if match:
stock_name = match.group(1)
stock_code = match.group(2)
file_date = os.path.getctime(file_path)
stock_data.append({
'date': file_date,
'stock_name': stock_name,
'stock_code': stock_code,
'file_name': file_name,
'file_date': file_date,
})
return stock_data
def write_to_excel(stock_data, excel_file):
df = pd.DataFrame(stock_data)
df.to_excel(excel_file)
stock_data = collect_data_from_files('path/to/folder')
write_to_excel(stock_data, 'path/to/excel_file')
可以使用 Python 的 Pandas 库来实现这个功能。
首先,可以使用 os 库和 glob 库来找到文件夹中的所有文本文件。然后可以使用 pandas.read_csv() 函数将文件的内容读入到 DataFrame 中。在这个过程中,可以使用正则表达式来提取文件中的股票名称和代码。
最后,可以使用 pandas 的 concat() 函数将所有文件的 DataFrame 合并到一个 DataFrame 中,然后使用 pandas 的 to_excel() 函数将其保存到 Excel 中。
文件夹中的所有文件的路径
file_paths = glob.glob(os.path.join(folder_path, '*.txt'))
初始化 DataFrame 用来存储所有文件的内容
df_all = pd.DataFrame(columns=['Date','Stock Name','Stock Code','From File Name','From File Date'])
遍历所有文件
for file_path in file_paths:
读取文件内容
with open(file_path, 'r') as f:
file_content = f.read()
通过正则表达式提取股票名称和代码
stock_name, stock_code = re.search(r'(.+)((.+))', file_content).groups()
获取文件名和日期
file_name = os.path.basename(file_path)
file_date = datetime.fromtimestamp(os.path.getmtime(file_path)).strftime("%Y-%m-%d")
#把文件信息写入Dataframe里
df_all = df_all.append({'Date':file_date,'Stock Name':stock_name,'Stock Code':stock_code,'From File Name':file_name,'From File Date':file_date}, ignore_index=True)
#写入Excel
df_all.to_excel('output.xlsx', index=False)
对于每天更新的问题,在上面的代码的基础上,可以在每天的脚本中增加一段读取已经存在的Excel文件的部分代码,然后将新读取的数据拼接到已经存在的Dataframe中,再将新数据存入excel中即可。
示例代码如下:
#读取已经存在的excel
existing_df = pd.read_excel('output.xlsx')
df_all = pd.concat([existing_df,df_all], ignore_index=True)
#写入Excel
df_all.to_excel('output.xlsx', index=False)
这样的话,你就可以每天运行脚本,它会将新的数据添加到已有的Excel表中,每次运行都会有新的数据,类似于在原来的基础上增加。
请注意,如果需要做去重处理,可以在df_all数据拼接之后进行drop_duplicate() 或者在保存前再次读取该excel进行去重.
先需要使用 os.listdir() 函数获取指定文件夹中的文件列表,然后遍历文件列表并使用 pandas.read_csv() 函数将文件内容读入 DataFrame 中。接下来需要解析文件名并提取其中的日期,可以使用正就表达式或其他方法来实现。
最后使用 pandas 的 to_excel() 方法将 DataFrame 写入 Excel 文件中,并设置保存追加的模式。
贴出部分代码供参考:
import os
import pandas as pd
# 指定文件夹路径
folder_path = 'path/to/folder'
# 获取文件列表
file_list = os.listdir(folder_path)
# 创建空 DataFrame
df = pd.DataFrame(columns=['date', 'stock_name', 'stock_code', 'file_name', 'file_date'])
# 遍历文件列表
for file_name in file_list:
# 解析文件名并提取日期
file_date = ...
with open(os.path.join(folder_path, file_name), 'r') as f:
file_content = f.read()
# 提取股票名称和代码
stock_name, stock_code = ...
# 添加新行到 DataFrame 中
df = df.append({'date': date, 'stock_name': stock_name, 'stock_code': stock_code, 'file_name': file_name, 'file_date': file_date}, ignore_index=True
接下来就可以使用 pandas 的 to_excel() 方法将 DataFrame 写入 Excel 文件中了,类似于这样:
# 指定 Excel 文件路径
excel_file = 'path/to/excel.xlsx'
# 将 DataFrame 写入 Excel 中,追加模式
df.to_excel(excel_file, index=False, mode='a')
这样就可以完成一次归集并写入 Excel 的操作。
如果需要每天接着之前的内容写入,可以将上面的代码放入一个循环中,每天运行一次。也可以使用 python 调度任务工具(如schedule,APScheduler等)在指定时间自动运行该程序。
需要注意如果是循环运行,需要添加判断是否为新增数据
仅供参考,望采纳,谢谢。
实现代码如下, 已测试:
import os
import pandas as pd
import time
root_dir = r'C:\Users\SESA694210\Desktop\development\test\每日文件夹'
resultList = []
for file_name in os.listdir(root_dir):
if file_name.endswith(".txt"):
file_path = os.path.join(root_dir, file_name)
file_date = time.strftime('%Y%m%d', time.localtime(os.path.getmtime(file_path)))
with open(file_path, "r", encoding='utf-8') as f:
for line in f.readlines():
parts = line.replace('\r', '').replace('\n', '').split('(') # 和文本文件一致
stock_name = parts[0]
stock_code = parts[1].replace(')', '') # 和文本文件一致
resultList.append([file_date, stock_name, str(stock_code), file_name.replace('.txt', '')])
# 读完的文件重命名, 避免后续再读入
os.rename(file_path, file_path.replace('.txt', '.txt.old'))
print(resultList)
columns = ['文件日期', '股票名称', '股票代码', '文件名称']
df = pd.DataFrame(resultList, columns=columns)
df1 = pd.DataFrame(columns=columns) # 空
excel_file = os.path.join(root_dir, '按日文件归集.xlsx')
if os.path.exists(excel_file):
df1 = pd.read_excel(excel_file, usecols=columns, dtype=object)
# 合并
df_sum = pd.concat([df1, df], axis=0)
df_sum.insert(loc=0, column='序号', value=range(1, len(df_sum) + 1))
print(df_sum)
# 写入文件
df_sum.to_excel(excel_file, encoding='utf-8', index=False)
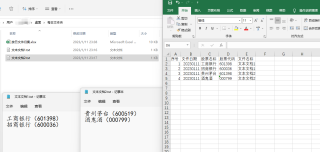
输出结果:
[['20230112', '工商银行', '601398', '文本文档1'], ['20230112', '招商银行', '600036', '文本文档1'], ['20230112', '贵州茅台', '600519', '文本文档2'], ['20230112', '酒鬼酒', '000799', '文本文档2']]
序号 文件日期 股票名称 股票代码 文件名称
0 1 20230112 工商银行 601398 文本文档1
1 2 20230112 招商银行 600036 文本文档1
2 3 20230112 贵州茅台 600519 文本文档2
3 4 20230112 酒鬼酒 000799 文本文档2
Process finished with exit code 0
按日文件归集.xlsx 文件:

解决思路:调用os库和pandas库来实现,借助DataFrame和ExcelWriter等函数获取信息,用re正则表达式定位。
import os
import re
import pandas as pd
folder_path = "path/to/folder"
file_list = []
for file_name in os.listdir(folder_path):
file_list.append(file_name)
columns = ['date','name','code','file_name','file_date']
df = pd.DataFrame(columns=columns)
for file_name in file_list:
file_path = os.path.join(folder_path, file_name)
with open(file_path, "r") as file:
file_content = file.read()
match = re.search(r"(.*)\((.*)\)", file_content)
if match:
name, code = match.groups()
date = pd.datetime.now()
file_date = os.path.getmtime(file_path)
df = df.append({'date':date,'name':name,'code':code,'file_name':file_name,'file_date':file_date},ignore_index=True)
# 将 DataFrame 写入 Excel
with pd.ExcelWriter("output.xlsx") as writer:
df.to_excel(writer, sheet_name='Sheet1')
```
仅供参考
因为要操作文件,包括excel文件,建议用 Pandas 库来实现,非常方便
可以使用 Python 的 os 库和 pandas 库来实现这个需求。首先,使用 os.listdir() 函数获取指定文件夹中的所有文件,然后遍历每个文件,读取文件内容,提取文件名和文件日期,将文件内容解析成 "股票名称(股票代码)" 的格式,并将所有信息存入 pandas DataFrame 中。
接下来使用pandas将这些数据写入Excel中,如果需要每天接着之前的内容写入,可以在每次读取数据前读取上一次写入的Excel文件,将数据追加到已有的数据中,再把整个DataFrame重新写入Excel。
具体代码可能需要根据文件夹路径、文件名格式等进行调整。
这个是最近整理的一些python常用文件操作,作为参考:【python文件操作——标准库和常用第三方库】
下方代码为获取文件和文件相关时间,和时间排序问题
```python
import os
from pathlib import Path
def get_file_list(file_path):
# 按照时间排序
dir_list = os.listdir(file_path)
if not dir_list:
return
else:
# 注意,这里使用lambda表达式,将文件按照最后修改时间顺序升序排列
# os.path.getmtime() 函数是获取文件最后修改时间
# os.path.getctime() 函数是获取文件最后创建时间
dir_list = sorted(dir_list, key=lambda x: os.path.getmtime(os.path.join(file_path, x)), reverse=True)
# 返回文件+时间的列表
# dir_list = [[x, os.path.getmtime(os.path.join(file_path, x))] for x in dir_list]
return dir_list
if __name__ == '__main__':
BASE_DIR = Path(__file__).resolve().parent
print(get_file_list(BASE_DIR))
# 结果 ['文件相关.py', '.idea', '.git', '电话组合排列.py', '深度合并dict.py', '内存泄漏.py']
```