python爬数据代码
本人想在指定网站页面使用python脚本爬数据,网站http://mmt.favor2.info/satellites/1383(网站可手动更换,但是页面是一样的格式),爬取内容为网站页面表哥内最后的T。
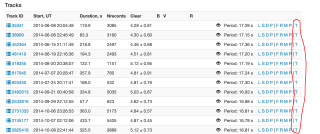
页面内所有红色标记都需要爬下来。
我看看,稍等 参数可以自己替换
望 采纳
import requests
import re
import wget
import os
import threading
headers= {
"User-Agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; Tablet PC 2.0; wbx 1.0.0; wbxapp 1.0.0; Zoom 3.6.0)"
}
def Download(url,savedir):
print('%s 正在下载 将保存至 %s\n' % (url.strip(),savedir),end = '')
wget.download(url,out = savedir)
print('%s 已下载完毕 已保存至 %s\n' % (url.strip(),savedir),end = '')
def LoadPage(url,savedir):
global headers
response = requests.get(url,headers = headers)
text = response.text.encode(response.encoding).decode(response.apparent_encoding)
result = re.findall('<a href=\"/satellites/track/(.*)/download\" title=\"Downoad track\">T</a>',text)
print('%s 中的下载地址已获取(共%d项)' % (url,len(result)))
threads = []
for sid in result:
thd = threading.Thread(target = Download,args = ('http://mmt.favor2.info/satellites/track/%s/download\n' % (sid),os.path.join(savedir,'track_%s.txt' % (sid)),))
thd.start()
threads.append(thd)
while len(threads) != 0:
threads[0].join()
threads.pop(0)
LoadPage('http://mmt.favor2.info/satellites/1383?page=3','./Data')

时间原因,只下载了三个,效果如上
很简单呀,可以做!
你可以使用 Python 的爬虫框架 BeautifulSoup 和 HTTP 库 requests 来爬取这个网站的数据。
首先,需要使用 requests 库发送 HTTP 请求来获取网页的 HTML 源代码。
然后,使用 BeautifulSoup 解析 HTML,并查找你想要的数据。你可以使用 BeautifulSoup 的 find 或 find_all 方法来查找特定的 HTML 标签,并访问它的内容。
例如,下面的代码演示了如何发送 HTTP 请求并使用 BeautifulSoup 解析网页:
import requests
from bs4 import BeautifulSoup
# Send an HTTP request to the URL of the webpage you want to access.
response = requests.get('http://mmt.favor2.info/satellites/1383')
# Parse the HTML of the webpage
soup = BeautifulSoup(response.text, 'html.parser')
# Find all the elements with the class "T"
elements = soup.find_all(class_='T')
# Print the text of each element
for element in elements:
print(element.text)
这样就可以爬取网站中的 T 了。
希望这些信息对你有所帮助!
可以看看我写的代码
import requests
from bs4 import BeautifulSoup
# 网站地址
url = "http://mmt.favor2.info/satellites/1383"
# 发送请求获取网页内容
response = requests.get(url)
html = response.text
# 使用 BeautifulSoup 解析网页
soup = BeautifulSoup(html, 'html.parser')
# 找到T链接
elements = soup.find_all(class_='T')
# 保存 T 值到文件
with open("T.txt", "w") as f:
f.write(T)
整个html都收到了,取哪些数据有用还不是你说了算
这网站很容易就可以取到那组T 吧

这个简单~等我
我来给你写一个,很简单的。