使用pandas快速提取表中的数字
有一个类似这样的pandas表:
df0 = pd.DataFrame([['x=6.2', 'y=6.3', 'z=6.7'], ['x=7.2', 'x=8.3','x=9.5']])
希望获得其中的所有数字,并存到numpy中。目前所使用的方法如下:
df0_np = np.zeros([df0.shape[0], 3])
for i in range(df0_np.shape[0]):
df0_np[i, :] = df0.iloc[i, :].str.extract(r'(\d+.\d+)').transpose()
print(df0_np)
得到结果如下:
[[6.2 6.3 6.7]
[7.2 8.3 9.5]]
由于str.extract()方法只能应用于series,不知道有什么更快捷的方法能够一次性应用于所有的dataframe,因此采用循环的方法解决。希望能够直接应用于dataframe对象获得最终的numpy数组,感谢。
可以使用pandas的apply函数来实现对整个DataFrame的操作。
- 定义一个函数extract_numbers,用于提取字符串中的数字,然后使用apply函数将这个函数应用于DataFrame的每一行,最后将提取出的数字存到一个新的DataFrame中。实现如下:
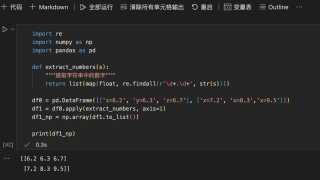
import re
import numpy as np
import pandas as pd
def extract_numbers(s):
"""提取字符串中的数字"""
return list(map(float, re.findall(r'\d+.\d+', str(s))))
df0 = pd.DataFrame([['x=6.2', 'y=6.3', 'z=6.7'], ['x=7.2', 'x=8.3','x=9.5']])
df1 = df0.apply(extract_numbers, axis=1)
df1_np = np.array(df1.to_list())
print(df1_np)
输出
[[6.2 6.3 6.7]
[7.2 8.3 9.5]]